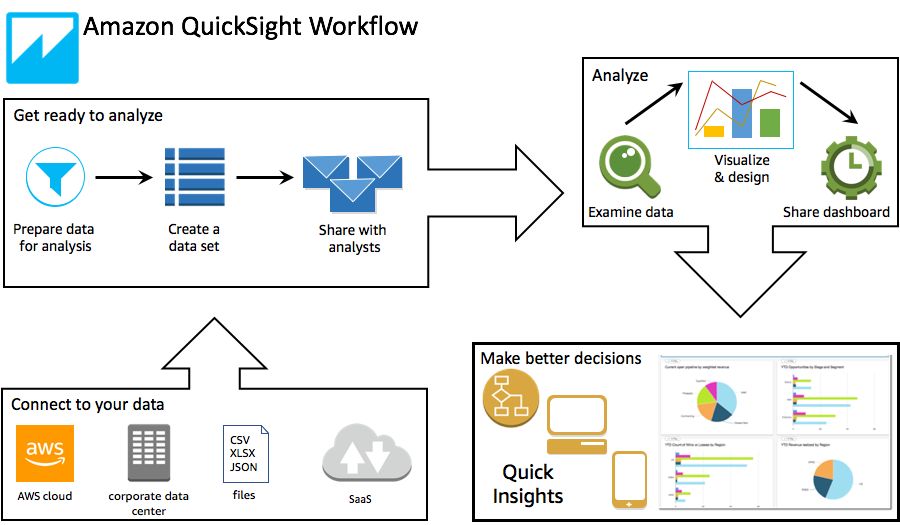
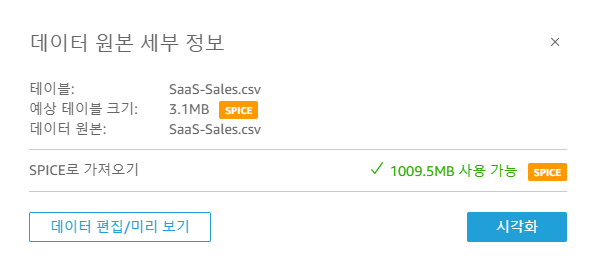
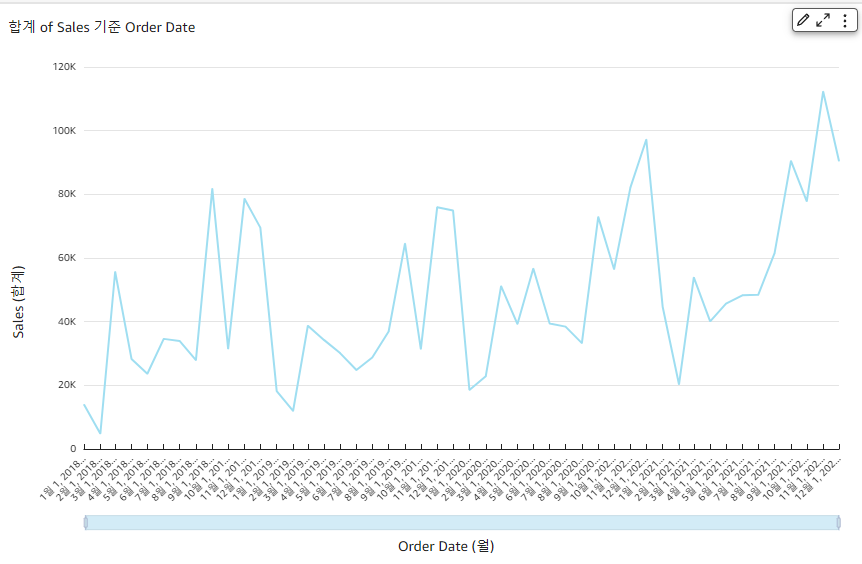
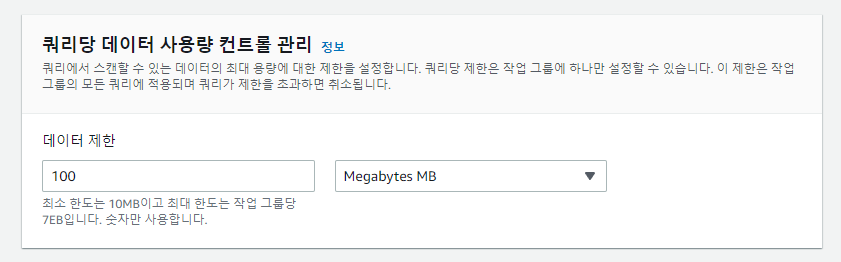
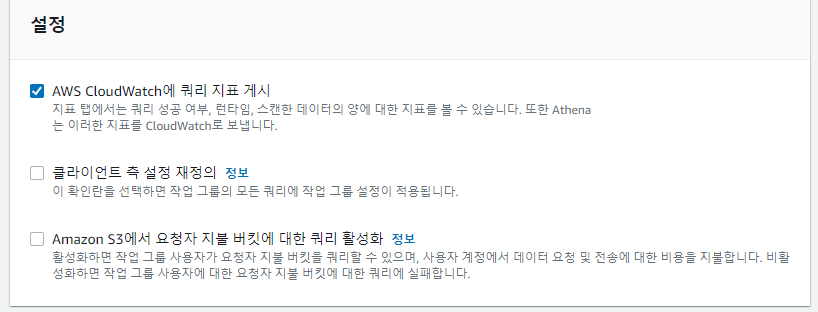
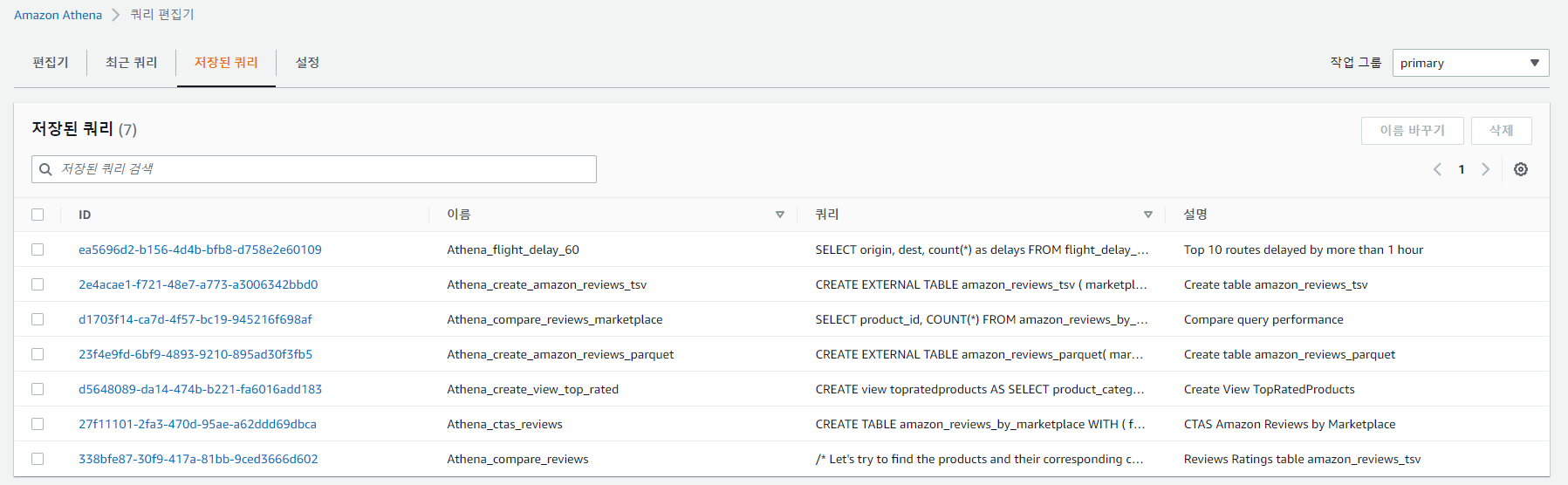
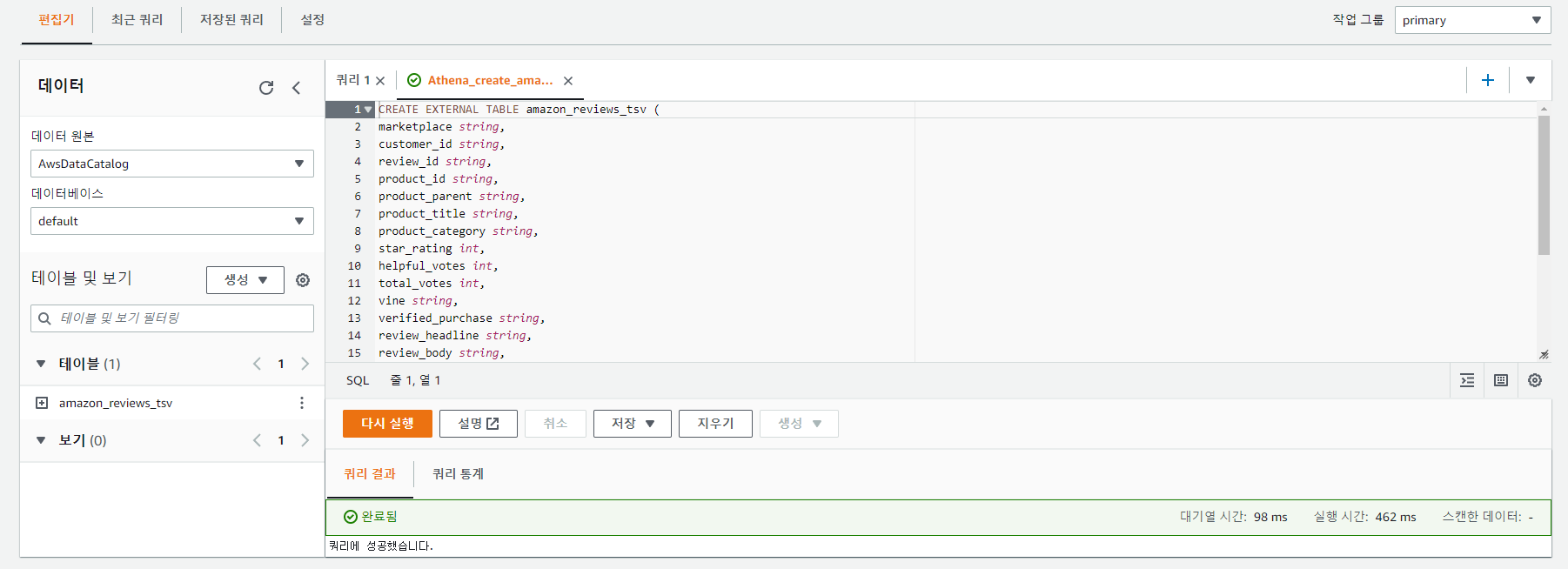
# Purpose: Creates Athena Workgroups, Named Queries, IAM Users via AWS CloudFormation
#===============================================================================
AWSTemplateFormatVersion: "2010-09-09"
Description: |
Athena Immersion Day - Creates Athena Workgroups, Named Queries, IAM Users
Resources:
AthenaWorkShopBucket:
Type: "AWS::S3::Bucket"
Properties:
BucketName: !Join [ "-", ["athena-workshop", Ref: "AWS::AccountId"]]
workgroupA:
Type: AWS::Athena::WorkGroup
Properties:
Name: workgroupA
RecursiveDeleteOption: true
WorkGroupConfiguration:
PublishCloudWatchMetricsEnabled: true
ResultConfiguration:
OutputLocation: !Join [ "", ["s3://" , Ref: AthenaWorkShopBucket, "/"]]
workgroupB:
Type: AWS::Athena::WorkGroup
Properties:
Name: workgroupB
RecursiveDeleteOption: true
workgroupIcebergpreview:
Type: AWS::Athena::WorkGroup
Properties:
Name: AmazonAthenaIcebergPreview
RecursiveDeleteOption: true
WorkGroupConfiguration:
EnforceWorkGroupConfiguration: true
EngineVersion:
SelectedEngineVersion: Athena engine version 2
PublishCloudWatchMetricsEnabled: true
ResultConfiguration:
OutputLocation: !Join [ "", ["s3://" , Ref: AthenaWorkShopBucket, "/"]]
amazonreviewstsv:
Type: AWS::Athena::NamedQuery
Properties:
Database: "default"
Description: "Create table amazon_reviews_tsv"
Name: "Athena_create_amazon_reviews_tsv"
QueryString: |
CREATE EXTERNAL TABLE amazon_reviews_tsv (
marketplace string,
customer_id string,
review_id string,
product_id string,
product_parent string,
product_title string,
product_category string,
star_rating int,
helpful_votes int,
total_votes int,
vine string,
verified_purchase string,
review_headline string,
review_body string,
review_date date,
year int)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
ESCAPED BY '\\'
LINES TERMINATED BY '\n'
LOCATION
's3://amazon-reviews-pds/tsv/'
TBLPROPERTIES ("skip.header.line.count"="1");
amazonreviewsparquet:
Type: AWS::Athena::NamedQuery
Properties:
Database: "default"
Description: "Create table amazon_reviews_parquet"
Name: "Athena_create_amazon_reviews_parquet"
QueryString: |
CREATE EXTERNAL TABLE amazon_reviews_parquet(
marketplace string,
customer_id string,
review_id string,
product_id string,
product_parent string,
product_title string,
star_rating int,
helpful_votes int,
total_votes int,
vine string,
verified_purchase string,
review_headline string,
review_body string,
review_date bigint,
year int)
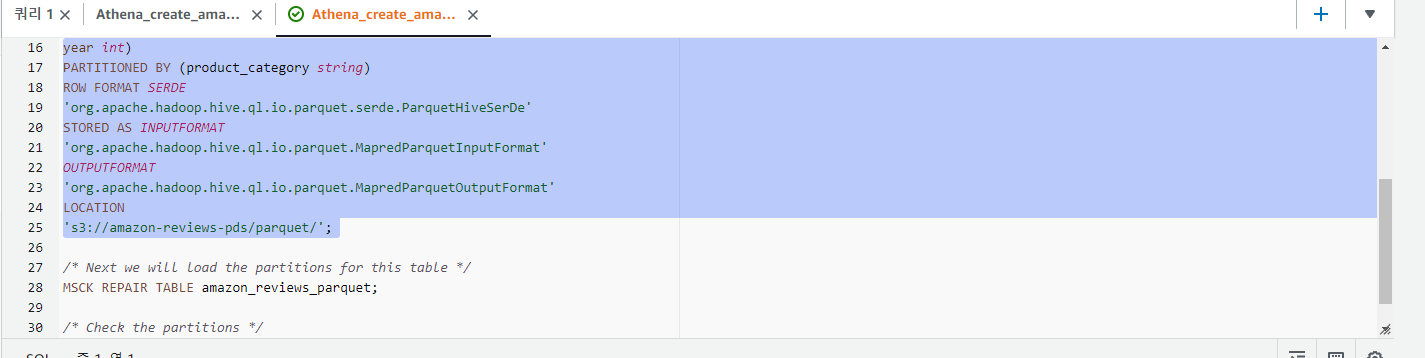
PARTITIONED BY (product_category string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
's3://amazon-reviews-pds/parquet/';
/* Next we will load the partitions for this table */
MSCK REPAIR TABLE amazon_reviews_parquet;
/* Check the partitions */
SHOW PARTITIONS amazon_reviews_parquet;
qryamazonreviewstsv:
Type: AWS::Athena::NamedQuery
Properties:
Database: "default"
Description: "Reviews Ratings table amazon_reviews_tsv"
Name: "Athena_compare_reviews"
QueryString: |
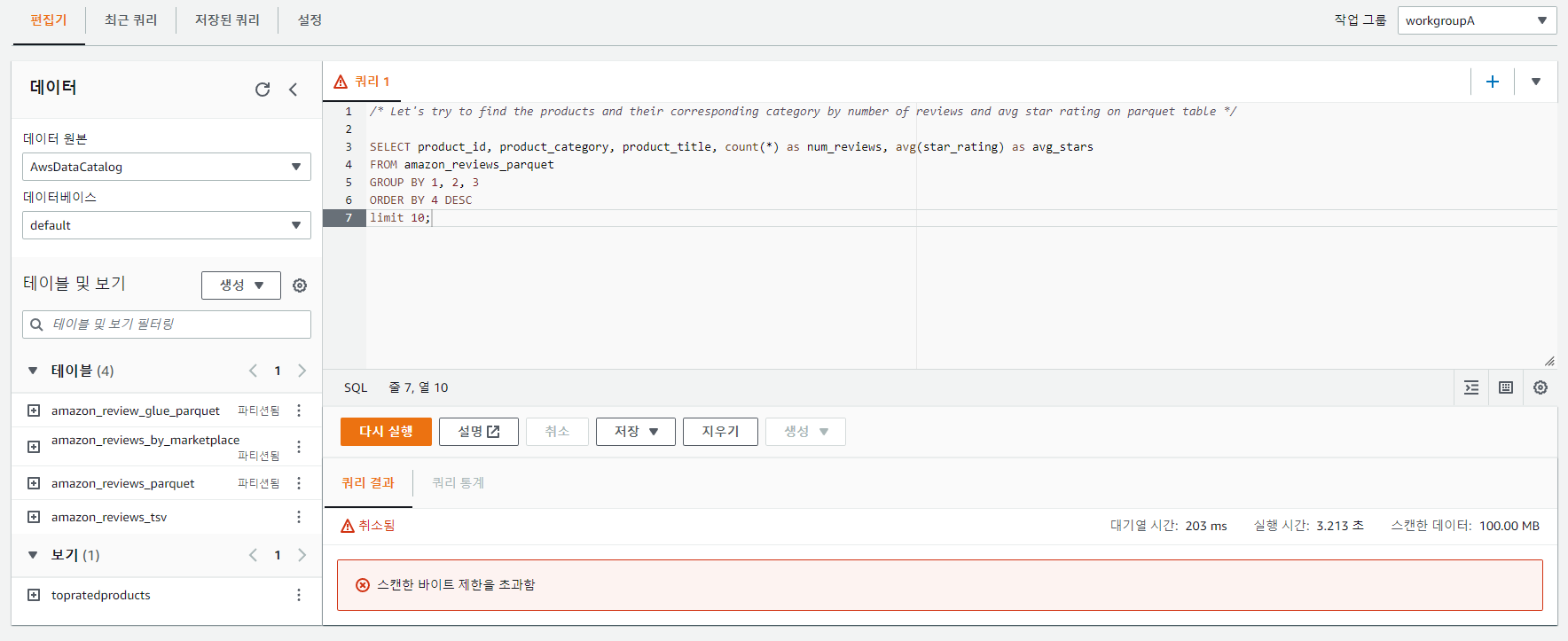
/* Let's try to find the products and their corresponding category by number of reviews and avg star rating */
SELECT product_id, product_category, product_title, count(*) as num_reviews, avg(star_rating) as avg_stars
FROM amazon_reviews_tsv
GROUP BY 1, 2, 3
ORDER BY 4 DESC
limit 10;
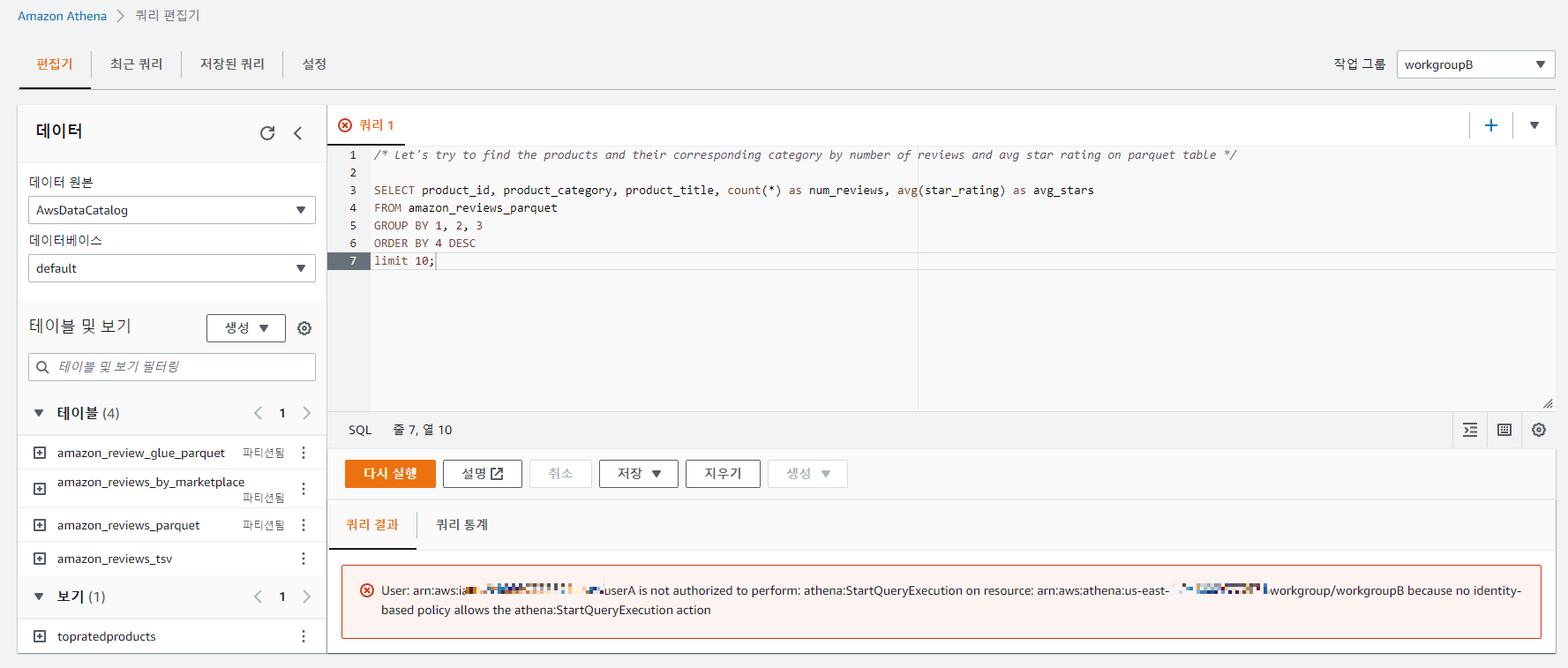
/* Let's try to find the products and their corresponding category by number of reviews and avg star rating on parquet table */
SELECT product_id, product_category, product_title, count(*) as num_reviews, avg(star_rating) as avg_stars
FROM amazon_reviews_parquet
GROUP BY 1, 2, 3
ORDER BY 4 DESC
limit 10;
/* Let's try to find the products by number of reviews and avg star rating in Mobile_Apps category */
SELECT product_id, product_title, count(*) as num_reviews, avg(star_rating) as avg_stars
FROM amazon_reviews_tsv where product_category='Mobile_Apps'
GROUP BY 1, 2
ORDER BY 3 DESC
limit 10;
/* Let's try to find the products by number of reviews and avg star rating in Mobile_Apps category */
SELECT product_id, product_title, count(*) as num_reviews, avg(star_rating) as avg_stars
FROM amazon_reviews_parquet where product_category='Mobile_Apps'
GROUP BY 1, 2
ORDER BY 3 DESC
limit 10;
TopReviewedStarRatedProductsv:
Type: AWS::Athena::NamedQuery
Properties:
Database: "default"
Description: "Create View TopRatedProducts"
Name: "Athena_create_view_top_rated"
QueryString: |
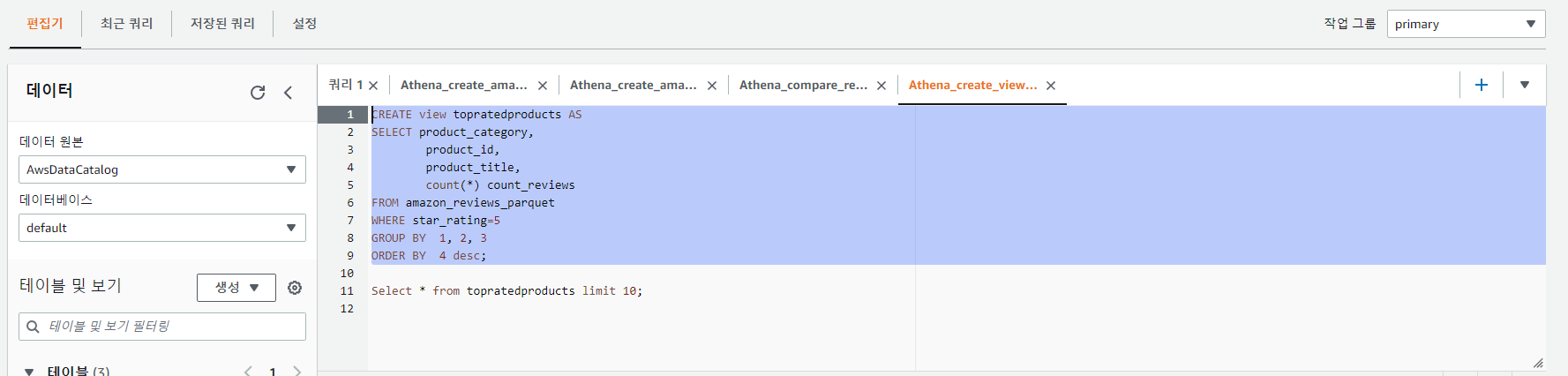
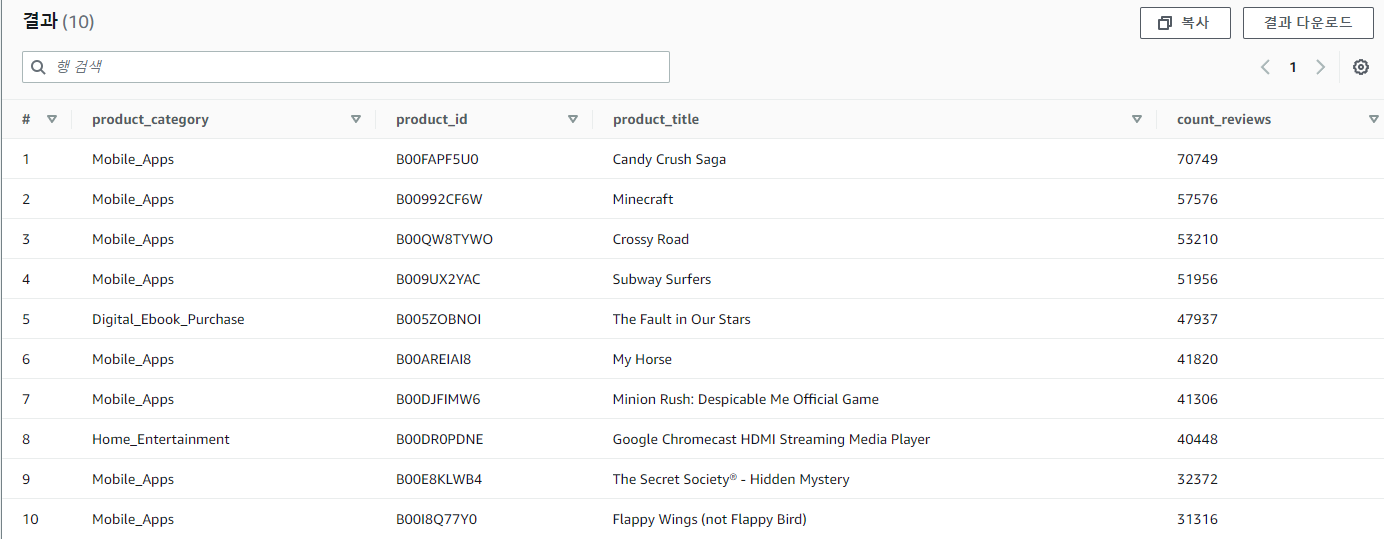
CREATE view topratedproducts AS
SELECT product_category,
product_id,
product_title,
count(*) count_reviews
FROM amazon_reviews_parquet
WHERE star_rating=5
GROUP BY 1, 2, 3
ORDER BY 4 desc;
Select * from topratedproducts limit 10;
ctas:
Type: AWS::Athena::NamedQuery
Properties:
Database: "default"
Description: "CTAS Amazon Reviews by Marketplace"
Name: "Athena_ctas_reviews"
QueryString: |
CREATE TABLE amazon_reviews_by_marketplace
WITH ( format='PARQUET', parquet_compression = 'SNAPPY', partitioned_by = ARRAY['marketplace', 'year'],
external_location = 's3://<<Athena-WorkShop-Bucket>>/athena-ctas-insert-into/') AS
SELECT customer_id,
review_id,
product_id,
product_parent,
product_title,
product_category,
star_rating,
helpful_votes,
total_votes,
verified_purchase,
review_headline,
review_body,
review_date,
marketplace,
year(review_date) AS year
FROM amazon_reviews_tsv
WHERE "$path" LIKE '%tsv.gz';
/* Let's try to find the products and their corresponding category by number of reviews and avg star rating for US marketplace in year 2015 */
SELECT product_id,
product_category,
product_title,
count(*) AS num_reviews,
avg(star_rating) AS avg_stars
FROM amazon_reviews_by_marketplace
WHERE marketplace='US'
AND year=2015
GROUP BY 1, 2, 3
ORDER BY 4 DESC limit 10;
comparereviews:
Type: AWS::Athena::NamedQuery
Properties:
Database: "default"
Description: "Compare query performance"
Name: "Athena_compare_reviews_marketplace"
QueryString: |
SELECT product_id, COUNT(*) FROM amazon_reviews_by_marketplace
WHERE marketplace='US' AND year = 2013
GROUP BY 1 ORDER BY 2 DESC LIMIT 10;
SELECT product_id, COUNT(*) FROM amazon_reviews_parquet
WHERE marketplace='US' AND year = 2013
GROUP BY 1 ORDER BY 2 DESC LIMIT 10;
SELECT product_id, COUNT(*) FROM amazon_reviews_tsv
WHERE marketplace='US' AND extract(year from review_date) = 2013
GROUP BY 1 ORDER BY 2 DESC LIMIT 10;
flights:
Type: AWS::Athena::NamedQuery
Properties:
Database: "default"
Description: "Top 10 routes delayed by more than 1 hour"
Name: "Athena_flight_delay_60"
QueryString: |
SELECT origin, dest, count(*) as delays
FROM flight_delay_parquet
WHERE depdelayminutes > 60
GROUP BY origin, dest
ORDER BY 3 DESC
LIMIT 10;
LabsUserPassword:
Type: "AWS::SecretsManager::Secret"
Properties:
Description: Athena Workshop User Password
Name: "/athenaworkshopuser/password"
GenerateSecretString:
SecretStringTemplate: '{}'
GenerateStringKey: "password"
PasswordLength: 30
userA:
Type: "AWS::IAM::User"
Properties:
Path: "/"
LoginProfile:
Password: !Sub '{{resolve:secretsmanager:${LabsUserPassword}:SecretString:password}}'
PasswordResetRequired: false
Policies:
- PolicyName: "Athena-WorkgroupA-Policy"
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Action:
- s3:Put*
- s3:Get*
- s3:List*
- glue:*
- cloudwatch:*
- athena:ListNamedQueries
- athena:ListWorkGroups
- athena:GetExecutionEngine
- athena:GetExecutionEngines
- athena:GetNamespace
- athena:GetCatalogs
- athena:GetNamespaces
- athena:GetTables
- athena:GetTable
Resource: "*"
- Effect: Allow
Action:
- athena:StartQueryExecution
- athena:GetQueryResults
- athena:DeleteNamedQuery
- athena:GetNamedQuery
- athena:ListQueryExecutions
- athena:StopQueryExecution
- athena:GetQueryResultsStream
- athena:ListNamedQueries
- athena:CreateNamedQuery
- athena:GetQueryExecution
- athena:BatchGetNamedQuery
- athena:BatchGetQueryExecution
Resource:
- !Join [ "", ["arn:aws:athena:us-east-1:", Ref: "AWS::AccountId" , ":workgroup/workgroupA"]]
- Effect: Allow
Action:
- athena:DeleteWorkGroup
- athena:UpdateWorkGroup
- athena:GetWorkGroup
- athena:CreateWorkGroup
Resource:
- !Join [ "", ["arn:aws:athena:us-east-1:", Ref: "AWS::AccountId" , ":workgroup/workgroupA"]]
UserName: "userA"
userB:
Type: "AWS::IAM::User"
Properties:
Path: "/"
LoginProfile:
Password: !Sub '{{resolve:secretsmanager:${LabsUserPassword}:SecretString:password}}'
PasswordResetRequired: false
Policies:
- PolicyName: "Athena-WorkgroupA-Policy"
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Action:
- s3:Put*
- s3:Get*
- s3:List*
- glue:*
- athena:ListWorkGroups
- athena:GetExecutionEngine
- athena:GetExecutionEngines
- athena:GetNamespace
- athena:GetCatalogs
- athena:GetNamespaces
- athena:GetTables
- athena:GetTable
Resource: "*"
- Effect: Allow
Action:
- athena:StartQueryExecution
- athena:GetQueryResults
- athena:DeleteNamedQuery
- athena:GetNamedQuery
- athena:ListQueryExecutions
- athena:StopQueryExecution
- athena:GetQueryResultsStream
- athena:ListNamedQueries
- athena:CreateNamedQuery
- athena:GetQueryExecution
- athena:BatchGetNamedQuery
- athena:BatchGetQueryExecution
Resource:
- !Join [ "", ["arn:aws:athena:us-east-1:", Ref: "AWS::AccountId" , ":workgroup/workgroupB"]]
- Effect: Allow
Action:
- athena:DeleteWorkGroup
- athena:UpdateWorkGroup
- athena:GetWorkGroup
- athena:CreateWorkGroup
Resource:
- !Join [ "", ["arn:aws:athena:us-east-1:", Ref: "AWS::AccountId" , ":workgroup/workgroupB"]]
UserName: "userB"
Outputs:
S3Bucket:
Description: S3 bucket
Value: !Ref AthenaWorkShopBucket
ConsoleLogin:
Description: LoginUrl
Value: !Join ["", ["https://", Ref: "AWS::AccountId" , ".signin.aws.amazon.com/console"]]
ConsolePassword:
Description: AWS Secrets URL to find the generated password for User A and User B
Value: !Sub 'https://console.aws.amazon.com/secretsmanager/home?region=${AWS::Region}#/secret?name=/athenaworkshopuser/password'