먼저 Athena가 뭐하는 친군지 살펴보자.
Amazon Athena
- 표준 SQL을 사용해 S3에 저장된 데이터를 간편하게 분석할 수 있는 대화식 쿼리 서버리스 서비스
- 그냥 단순히 S3에 저장된 데이터를 가리키고 스키마를 정의한 후 표준 SQL을 사용하여 쿼리를 시작하면 됨
- AWS Glue Data Catalog와 즉시 통합됨
- 다양한 서비스에 걸쳐 통합된 메타데이터 리포지토리를 생성하고, 데이터 원본을 크롤링하여 스키마를 검색하고 카탈로그를 신규 및 수정된 테이블 정의와 파티션 정의로 채우며, 스키마 버전을 관리할 수 있음
- 기능
- 표준 SQL을 사용한 간편한 쿼리: 오픈 소스 분산 SQL 쿼리 엔진(Presto) 사용
- 쿼리당 비용 지불: 실행한 쿼리에 대한 비용 지불(각 쿼리에서 스캔한 데이터 양에 따라 요금 부과)
- 빠른 성능: 자동으로 쿼리를 병렬로 실행, 대규모 데이터 세트에서도 빠른 결과 얻음
- 기계학습: SQL 쿼리에서 SageMaker 기계학습 모델을 호출하여 추론 실행 가능
등.. 많은 기능이 있다! 그러면 이러한 좋은 서비스 Athena를 사용해볼까?
aws workshop을 따라 가는 중..
- CloudFormation
CloudFormation(버지니아 북부)를 통해 밑바탕을 깔자.
(template)
# Purpose: Creates Athena Workgroups, Named Queries, IAM Users via AWS CloudFormation
#===============================================================================
AWSTemplateFormatVersion: "2010-09-09"
Description: |
Athena Immersion Day - Creates Athena Workgroups, Named Queries, IAM Users
Resources:
AthenaWorkShopBucket:
Type: "AWS::S3::Bucket"
Properties:
BucketName: !Join [ "-", ["athena-workshop", Ref: "AWS::AccountId"]]
workgroupA:
Type: AWS::Athena::WorkGroup
Properties:
Name: workgroupA
RecursiveDeleteOption: true
WorkGroupConfiguration:
PublishCloudWatchMetricsEnabled: true
ResultConfiguration:
OutputLocation: !Join [ "", ["s3://" , Ref: AthenaWorkShopBucket, "/"]]
workgroupB:
Type: AWS::Athena::WorkGroup
Properties:
Name: workgroupB
RecursiveDeleteOption: true
workgroupIcebergpreview:
Type: AWS::Athena::WorkGroup
Properties:
Name: AmazonAthenaIcebergPreview
RecursiveDeleteOption: true
WorkGroupConfiguration:
EnforceWorkGroupConfiguration: true
EngineVersion:
SelectedEngineVersion: Athena engine version 2
PublishCloudWatchMetricsEnabled: true
ResultConfiguration:
OutputLocation: !Join [ "", ["s3://" , Ref: AthenaWorkShopBucket, "/"]]
amazonreviewstsv:
Type: AWS::Athena::NamedQuery
Properties:
Database: "default"
Description: "Create table amazon_reviews_tsv"
Name: "Athena_create_amazon_reviews_tsv"
QueryString: |
CREATE EXTERNAL TABLE amazon_reviews_tsv (
marketplace string,
customer_id string,
review_id string,
product_id string,
product_parent string,
product_title string,
product_category string,
star_rating int,
helpful_votes int,
total_votes int,
vine string,
verified_purchase string,
review_headline string,
review_body string,
review_date date,
year int)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
ESCAPED BY '\\'
LINES TERMINATED BY '\n'
LOCATION
's3://amazon-reviews-pds/tsv/'
TBLPROPERTIES ("skip.header.line.count"="1");
amazonreviewsparquet:
Type: AWS::Athena::NamedQuery
Properties:
Database: "default"
Description: "Create table amazon_reviews_parquet"
Name: "Athena_create_amazon_reviews_parquet"
QueryString: |
CREATE EXTERNAL TABLE amazon_reviews_parquet(
marketplace string,
customer_id string,
review_id string,
product_id string,
product_parent string,
product_title string,
star_rating int,
helpful_votes int,
total_votes int,
vine string,
verified_purchase string,
review_headline string,
review_body string,
review_date bigint,
year int)
PARTITIONED BY (product_category string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
's3://amazon-reviews-pds/parquet/';
/* Next we will load the partitions for this table */
MSCK REPAIR TABLE amazon_reviews_parquet;
/* Check the partitions */
SHOW PARTITIONS amazon_reviews_parquet;
qryamazonreviewstsv:
Type: AWS::Athena::NamedQuery
Properties:
Database: "default"
Description: "Reviews Ratings table amazon_reviews_tsv"
Name: "Athena_compare_reviews"
QueryString: |
/* Let's try to find the products and their corresponding category by number of reviews and avg star rating */
SELECT product_id, product_category, product_title, count(*) as num_reviews, avg(star_rating) as avg_stars
FROM amazon_reviews_tsv
GROUP BY 1, 2, 3
ORDER BY 4 DESC
limit 10;
/* Let's try to find the products and their corresponding category by number of reviews and avg star rating on parquet table */
SELECT product_id, product_category, product_title, count(*) as num_reviews, avg(star_rating) as avg_stars
FROM amazon_reviews_parquet
GROUP BY 1, 2, 3
ORDER BY 4 DESC
limit 10;
/* Let's try to find the products by number of reviews and avg star rating in Mobile_Apps category */
SELECT product_id, product_title, count(*) as num_reviews, avg(star_rating) as avg_stars
FROM amazon_reviews_tsv where product_category='Mobile_Apps'
GROUP BY 1, 2
ORDER BY 3 DESC
limit 10;
/* Let's try to find the products by number of reviews and avg star rating in Mobile_Apps category */
SELECT product_id, product_title, count(*) as num_reviews, avg(star_rating) as avg_stars
FROM amazon_reviews_parquet where product_category='Mobile_Apps'
GROUP BY 1, 2
ORDER BY 3 DESC
limit 10;
TopReviewedStarRatedProductsv:
Type: AWS::Athena::NamedQuery
Properties:
Database: "default"
Description: "Create View TopRatedProducts"
Name: "Athena_create_view_top_rated"
QueryString: |
CREATE view topratedproducts AS
SELECT product_category,
product_id,
product_title,
count(*) count_reviews
FROM amazon_reviews_parquet
WHERE star_rating=5
GROUP BY 1, 2, 3
ORDER BY 4 desc;
Select * from topratedproducts limit 10;
ctas:
Type: AWS::Athena::NamedQuery
Properties:
Database: "default"
Description: "CTAS Amazon Reviews by Marketplace"
Name: "Athena_ctas_reviews"
QueryString: |
CREATE TABLE amazon_reviews_by_marketplace
WITH ( format='PARQUET', parquet_compression = 'SNAPPY', partitioned_by = ARRAY['marketplace', 'year'],
external_location = 's3://<<Athena-WorkShop-Bucket>>/athena-ctas-insert-into/') AS
SELECT customer_id,
review_id,
product_id,
product_parent,
product_title,
product_category,
star_rating,
helpful_votes,
total_votes,
verified_purchase,
review_headline,
review_body,
review_date,
marketplace,
year(review_date) AS year
FROM amazon_reviews_tsv
WHERE "$path" LIKE '%tsv.gz';
/* Let's try to find the products and their corresponding category by number of reviews and avg star rating for US marketplace in year 2015 */
SELECT product_id,
product_category,
product_title,
count(*) AS num_reviews,
avg(star_rating) AS avg_stars
FROM amazon_reviews_by_marketplace
WHERE marketplace='US'
AND year=2015
GROUP BY 1, 2, 3
ORDER BY 4 DESC limit 10;
comparereviews:
Type: AWS::Athena::NamedQuery
Properties:
Database: "default"
Description: "Compare query performance"
Name: "Athena_compare_reviews_marketplace"
QueryString: |
SELECT product_id, COUNT(*) FROM amazon_reviews_by_marketplace
WHERE marketplace='US' AND year = 2013
GROUP BY 1 ORDER BY 2 DESC LIMIT 10;
SELECT product_id, COUNT(*) FROM amazon_reviews_parquet
WHERE marketplace='US' AND year = 2013
GROUP BY 1 ORDER BY 2 DESC LIMIT 10;
SELECT product_id, COUNT(*) FROM amazon_reviews_tsv
WHERE marketplace='US' AND extract(year from review_date) = 2013
GROUP BY 1 ORDER BY 2 DESC LIMIT 10;
flights:
Type: AWS::Athena::NamedQuery
Properties:
Database: "default"
Description: "Top 10 routes delayed by more than 1 hour"
Name: "Athena_flight_delay_60"
QueryString: |
SELECT origin, dest, count(*) as delays
FROM flight_delay_parquet
WHERE depdelayminutes > 60
GROUP BY origin, dest
ORDER BY 3 DESC
LIMIT 10;
LabsUserPassword:
Type: "AWS::SecretsManager::Secret"
Properties:
Description: Athena Workshop User Password
Name: "/athenaworkshopuser/password"
GenerateSecretString:
SecretStringTemplate: '{}'
GenerateStringKey: "password"
PasswordLength: 30
userA:
Type: "AWS::IAM::User"
Properties:
Path: "/"
LoginProfile:
Password: !Sub '{{resolve:secretsmanager:${LabsUserPassword}:SecretString:password}}'
PasswordResetRequired: false
Policies:
- PolicyName: "Athena-WorkgroupA-Policy"
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Action:
- s3:Put*
- s3:Get*
- s3:List*
- glue:*
- cloudwatch:*
- athena:ListNamedQueries
- athena:ListWorkGroups
- athena:GetExecutionEngine
- athena:GetExecutionEngines
- athena:GetNamespace
- athena:GetCatalogs
- athena:GetNamespaces
- athena:GetTables
- athena:GetTable
Resource: "*"
- Effect: Allow
Action:
- athena:StartQueryExecution
- athena:GetQueryResults
- athena:DeleteNamedQuery
- athena:GetNamedQuery
- athena:ListQueryExecutions
- athena:StopQueryExecution
- athena:GetQueryResultsStream
- athena:ListNamedQueries
- athena:CreateNamedQuery
- athena:GetQueryExecution
- athena:BatchGetNamedQuery
- athena:BatchGetQueryExecution
Resource:
- !Join [ "", ["arn:aws:athena:us-east-1:", Ref: "AWS::AccountId" , ":workgroup/workgroupA"]]
- Effect: Allow
Action:
- athena:DeleteWorkGroup
- athena:UpdateWorkGroup
- athena:GetWorkGroup
- athena:CreateWorkGroup
Resource:
- !Join [ "", ["arn:aws:athena:us-east-1:", Ref: "AWS::AccountId" , ":workgroup/workgroupA"]]
UserName: "userA"
userB:
Type: "AWS::IAM::User"
Properties:
Path: "/"
LoginProfile:
Password: !Sub '{{resolve:secretsmanager:${LabsUserPassword}:SecretString:password}}'
PasswordResetRequired: false
Policies:
- PolicyName: "Athena-WorkgroupA-Policy"
PolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Action:
- s3:Put*
- s3:Get*
- s3:List*
- glue:*
- athena:ListWorkGroups
- athena:GetExecutionEngine
- athena:GetExecutionEngines
- athena:GetNamespace
- athena:GetCatalogs
- athena:GetNamespaces
- athena:GetTables
- athena:GetTable
Resource: "*"
- Effect: Allow
Action:
- athena:StartQueryExecution
- athena:GetQueryResults
- athena:DeleteNamedQuery
- athena:GetNamedQuery
- athena:ListQueryExecutions
- athena:StopQueryExecution
- athena:GetQueryResultsStream
- athena:ListNamedQueries
- athena:CreateNamedQuery
- athena:GetQueryExecution
- athena:BatchGetNamedQuery
- athena:BatchGetQueryExecution
Resource:
- !Join [ "", ["arn:aws:athena:us-east-1:", Ref: "AWS::AccountId" , ":workgroup/workgroupB"]]
- Effect: Allow
Action:
- athena:DeleteWorkGroup
- athena:UpdateWorkGroup
- athena:GetWorkGroup
- athena:CreateWorkGroup
Resource:
- !Join [ "", ["arn:aws:athena:us-east-1:", Ref: "AWS::AccountId" , ":workgroup/workgroupB"]]
UserName: "userB"
Outputs:
S3Bucket:
Description: S3 bucket
Value: !Ref AthenaWorkShopBucket
ConsoleLogin:
Description: LoginUrl
Value: !Join ["", ["https://", Ref: "AWS::AccountId" , ".signin.aws.amazon.com/console"]]
ConsolePassword:
Description: AWS Secrets URL to find the generated password for User A and User B
Value: !Sub 'https://console.aws.amazon.com/secretsmanager/home?region=${AWS::Region}#/secret?name=/athenaworkshopuser/password'
스택의 리소스나 이벤트를 확인해보면 생성 결과 → 쿼리문 파일들 + Athena 작업그룹 + IAM User A/B + S3 버킷 정도?
사실 이번 포스팅에서 User를 나누는 의미는 없다. 나중에 이어서 실습할 내용들에 있어서 필요한 유저들..
- Dataset 확인
데이터셋은 workshop에서 제공해주는 s3 버킷에 담겨있다.
https://console.aws.amazon.com/s3/home?region=us-east-1&bucket=amazon-reviews-pds
- Athena 기본 설정
작업 그룹에 대해 CloudWatch 지표를 활성화 한다.

CloudFormation을 통해 만들어진 작업 그룹들이다. 현재는 primary 기준으로 진행할 것!
(primary → 편집)
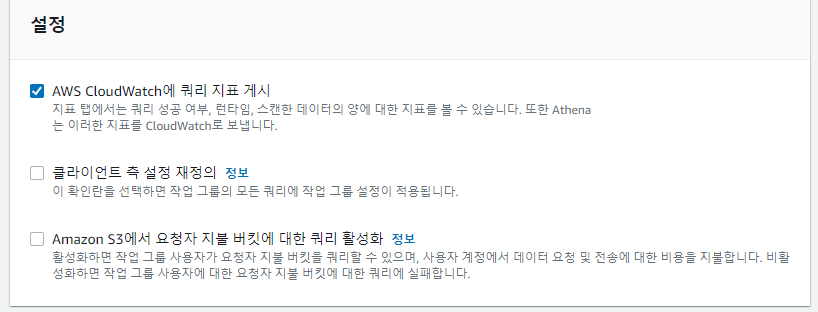
쿼리들을 실행하기 전에 먼저 Athena 설정에서 S3 버킷을 지정해줘야한다.
쿼리 편집기 → 설정보기

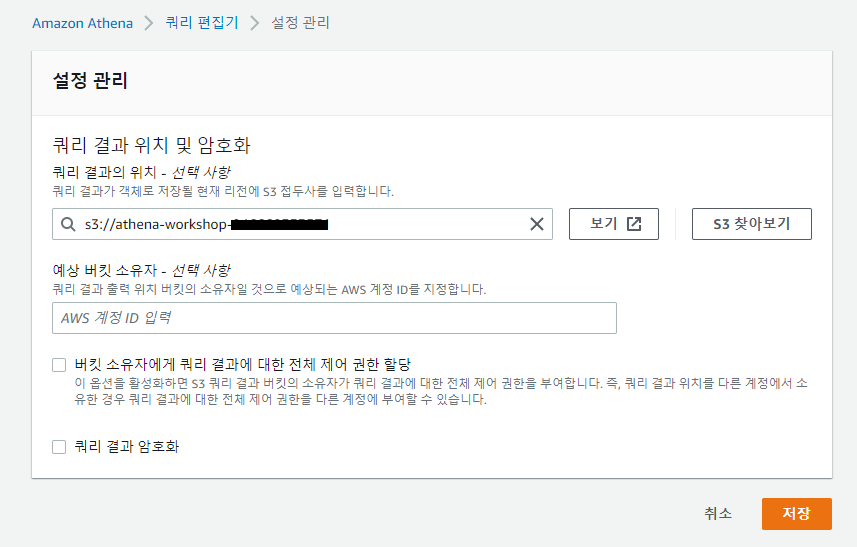
CloudFormation에서 생성했던 s3로 지정해준다.
- Athena - 테이블 생성 및 쿼리 실행

default 데이터베이스에서 실행할 예정. 만약 데이터베이스가 없다면 'CREATE database default' 실행.
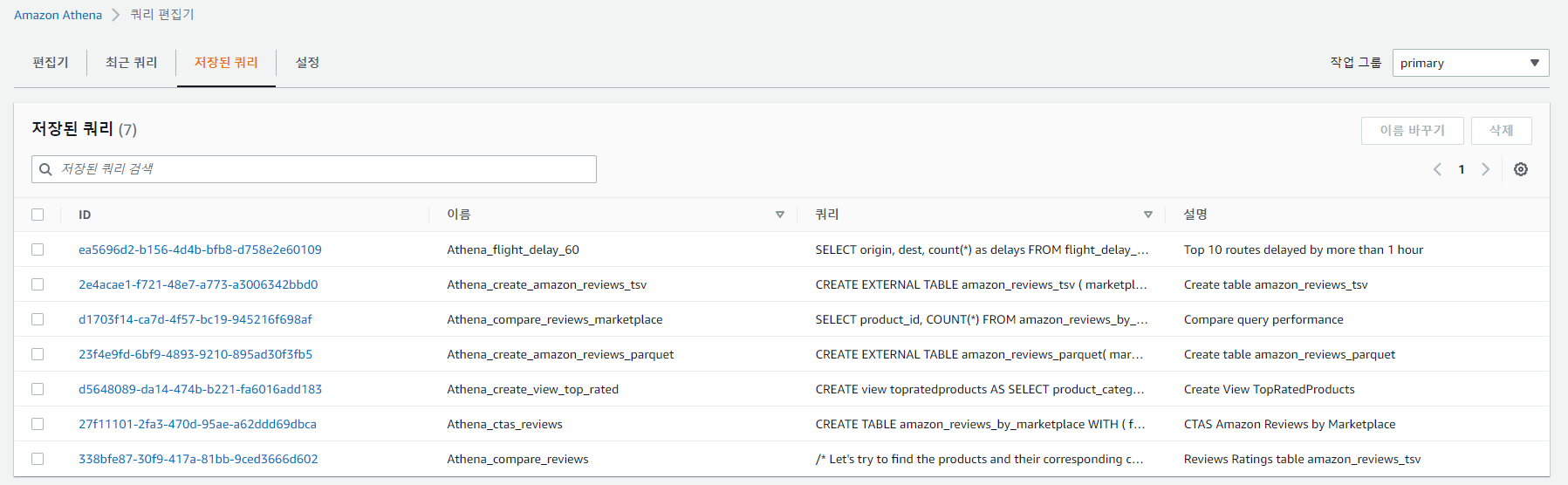
저장된 쿼리에서 Athena_create_amazon_review_tsv를 클릭후 편집기에 해당 쿼리문이 열리면 실행하자.
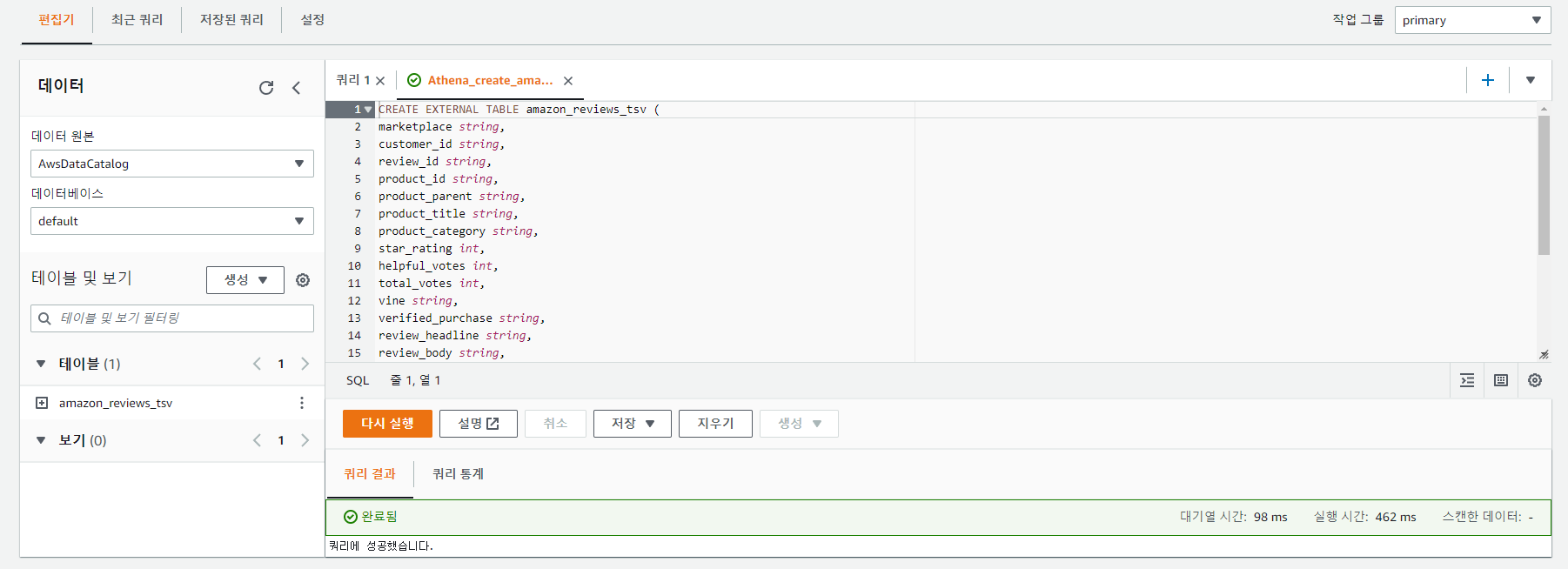
위 이미지와 같이 테이블이 만들어지면 성공
다음으론 저장된 쿼리에서 Athena_create_amazon_reviews_parquet를 클릭.
쿼리문에서 한 번에 하나의 쿼리를 선택하고 실행하자.(주석 기준으로 나눠서 드래그 후 실행)
딱 여기까지.. 다음 쿼리문들은 파티셔닝 관련 명령이다.
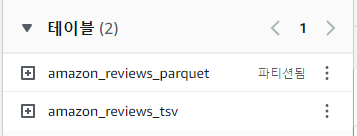
테이블 하나 더 생김!
- Athena - Partitioning Data
데이터를 분할하여 각 쿼리에서 스캔하는 데이터의 양을 제한하여 성능을 개선하고 비용을 절감할 수있음.
모든 키로 데이터를 분할할 수 있다. (보통 시간을 기준으로 데이터를 분할)
- 참고: https://docs.aws.amazon.com/ko_kr/athena/latest/ug/partitions.html
그럼 amazon_reviews_parquet 테이블을 기준으로 파티셔닝을 해보자.

위와 같이 두 명령을 각각 실행해보자.
그러면 파티션 추가 완료.
- Athena - 테이블 간 성능 테스트
저장된 쿼리에서 Athena_compare_reviews를 열자.
쿼리를 하나씩 선택해서 실행해 각 결과를 비교해보자.(스캔한 데이터 양과 소요 시간 차이 확인)
파티셔닝 전의 테이블: amazon_reviews_tsv


파티셔닝 후의 테이블: amazon_reviews_parquet


확실히 파티셔닝 후의 테이블의 성능이 뛰어나다는 것을 확인할 수 있다.
기본적인 SQL문(Select From 뭐시기... 이런 것)들은 알고 있는데..
파티셔닝 관련한 명령은 알지 못해서.. 간단히 정리해본다.
파티션을 사용하는 테이블을 생성하려면 CREATE TABLE 문에 PARTITIONED BY 절을 사용
기본 문법:
CREATE EXTERNAL TABLE users (
first string,
last string,
username string
)
PARTITIONED BY (id string)
STORED AS parquet
LOCATION 's3://DOC-EXAMPLE-BUCKET/folder/'테이블을 생성하고 쿼리를 위해 파티션에 데이터를 로드하는 명령
(참고로 parquet(파켓)은 Apache Hadoop 에코 시스템의 오픈소스 열 지향 데이터 저장 형식)
이후에 Hive 스타일 파티션의 경우 MSCK REPAIR TABLE을 실행(지금 했던 방식)
아니라면 ALTER TABLE ADD PARTITON을 사용해 파티션을 수동으로 추가
CREATE EXTERNAL TABLE amazon_reviews_parquet(
marketplace string,
customer_id string,
review_id string,
product_id string,
product_parent string,
product_title string,
star_rating int,
helpful_votes int,
total_votes int,
vine string,
verified_purchase string,
review_headline string,
review_body string,
review_date bigint,
year int)
PARTITIONED BY (product_category string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
's3://amazon-reviews-pds/parquet/';
/* Next we will load the partitions for this table */
MSCK REPAIR TABLE amazon_reviews_parquet;
/* Check the partitions */
SHOW PARTITIONS amazon_reviews_parquet;위의 코드블럭은 실습 진행하면서 사용했던 쿼리문이다.(어렵다 어려워...)
❗ 다음 포스팅에선 Glue와 어떤 식으로 통합해 사용하는지 알아보자 ❗
'Cloud > AWS' 카테고리의 다른 글
| [AWS] Amazon Athena 사용법 -3 (0) | 2022.11.20 |
|---|---|
| [AWS] Amazon Athena 사용법 -2 + Glue(Crawler) 활용 (1) | 2022.11.19 |
| [AWS] Step Functions (0) | 2022.11.18 |
| [AWS] Spot Fleet (0) | 2022.11.16 |
| [AWS] Lambda와 RDS Proxy (0) | 2022.11.14 |