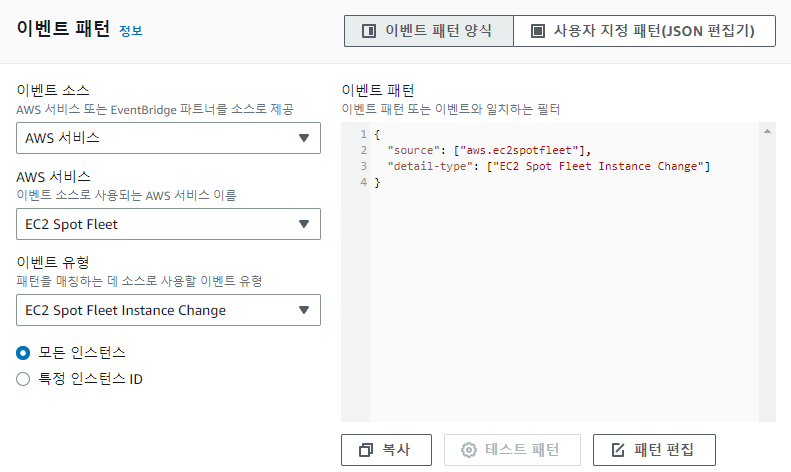
대부분의 경우 데이터 레이크 또는 테이블로 들어오는 raw data는 csv 또는 텍스트 형식이다.
이런 형식은 Athena, 기타 엔진으로 쿼리하는 데 최적이 아니다. 데이터를 parquet과 같은 포맷으로 변환하는 것이 좋다.
CTAS(Create Table As Select) 쿼리를 사용해 테이블을 tsv 형식에서 parquet 포맷으로 변환하고 압축 및 분할을 통해 저장할 것..
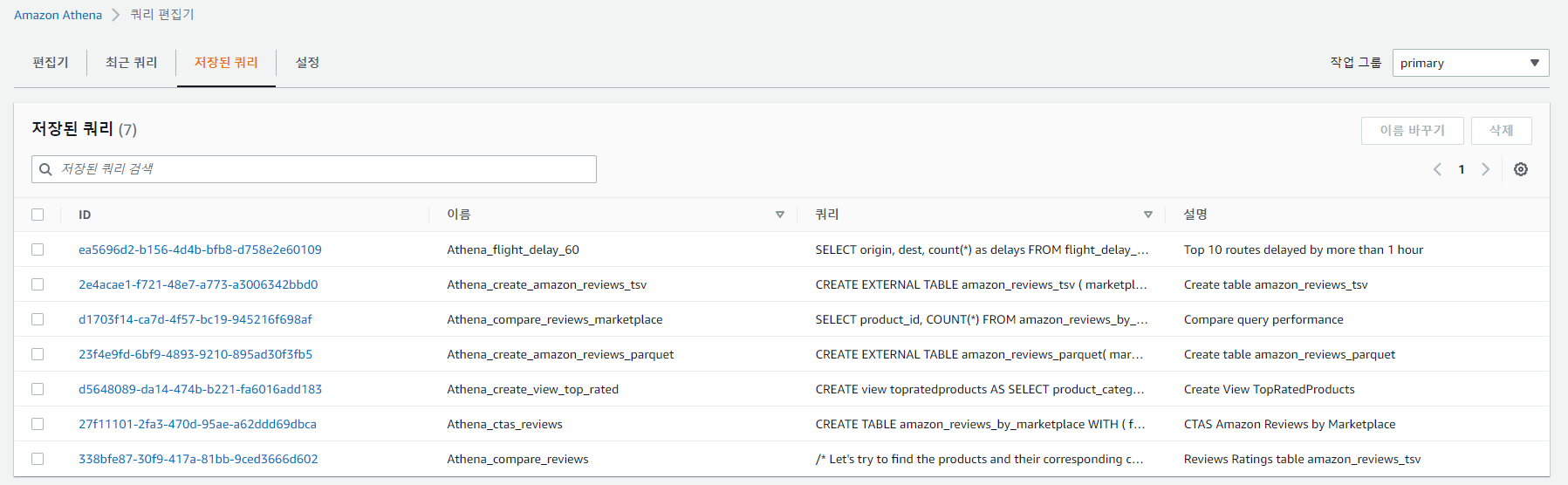
저장된 쿼리에서 Athena_ctas_reviews를 실행해보자
(s3 버킷 이름을 잘 설정 해주자!)
다음 쿼리를 실행하면 다음과 같이 결과를 볼 수 있다.
명령들을 좀 살펴보자!
CREATE TABLE amazon_reviews_by_marketplace
WITH ( format='PARQUET', parquet_compression = 'SNAPPY', partitioned_by = ARRAY['marketplace', 'year'],
external_location = 's3://<<Bucket-name>>/athena-ctas-insert-into/') AS
SELECT customer_id,
review_id,
product_id,
product_parent,
product_title,
product_category,
star_rating,
helpful_votes,
total_votes,
verified_purchase,
review_headline,
review_body,
review_date,
marketplace,
year(review_date) AS year
FROM amazon_reviews_tsv
WHERE "$path" LIKE '%tsv.gz';
/* Let's try to find the products and their corresponding category by number of reviews and avg star rating for US marketplace in year 2015 */
SELECT product_id,
product_category,
product_title,
count(*) AS num_reviews,
avg(star_rating) AS avg_stars
FROM amazon_reviews_by_marketplace
WHERE marketplace='US'
AND year=2015
GROUP BY 1, 2, 3
ORDER BY 4 DESC limit 10;
parquet_compression = 'SNAPPY' 같은 경우는 압축 방식을 정하는 것..
Like 구문: SELECT * FROM [table name] WHERE [column] LIKE [condition];
부분적으로 일치하는 컬럼을 찾을 때 사용
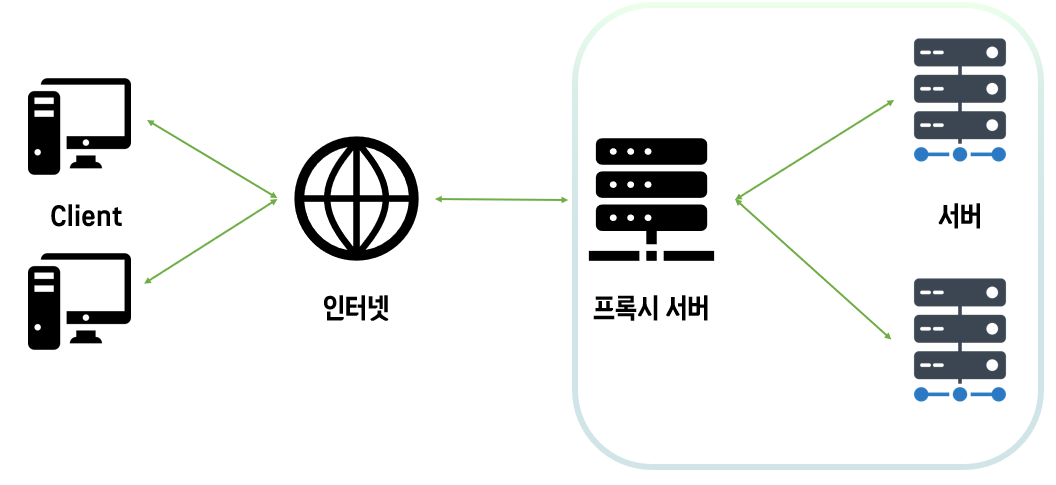
Athena Workgroups
Workgroup: 사용자, 팀, 애플리케이션 또는 워크로드를 분리하고 각 쿼리 또는 전체 workgroup이 처리할 수 있는 데이터 양에 대한 제한을 설정하고 비용을 추적한다.
"Workgroup이 리소스 역할을 하기 때문에 리소스 수준 ID 기반 정책을 사용해 특정 workgroup에 대한 액세스 제어 가능!"
저번 포스팅의 테이블 생성 실습에서 primary 작업 그룹에 대한 CloudWatch 메트릭을 활성화했다.
CloudWatch 지표를 확인해보자(작업 그룹 → primary → 지표)
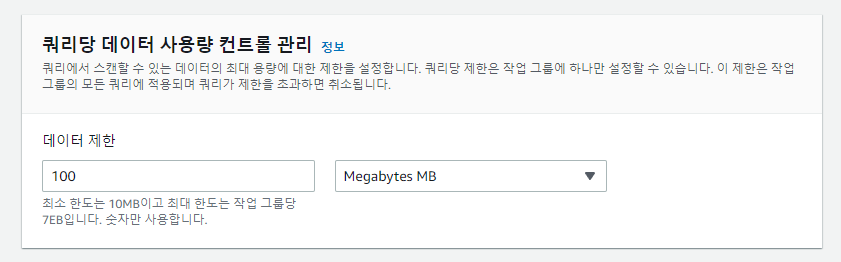
데이터 사용 제한을 설정해보자.
workgroupA를 클릭한 뒤 편집에 들어가 해당 데이터를 제한하자.
CloudFormation을 열고 스택 출력에 들어가 ConsolePassword 링크 클릭(AWS Secrets Manager로 이동)
해당 암호 값 검색을 통해 비밀번호를 확인하자.
시크릿 탭을 열어
IAM user name: userA
Password: 복사한 비밀번호 로 로그인하자.
Athena 콘솔을 열고 쿼리 결과 위치에 primary 위치를 입력한 다음 wrokgroupA를 선택하자.
(참고로 현재 실습은 버지니아 북부에서 진행 중이다!)
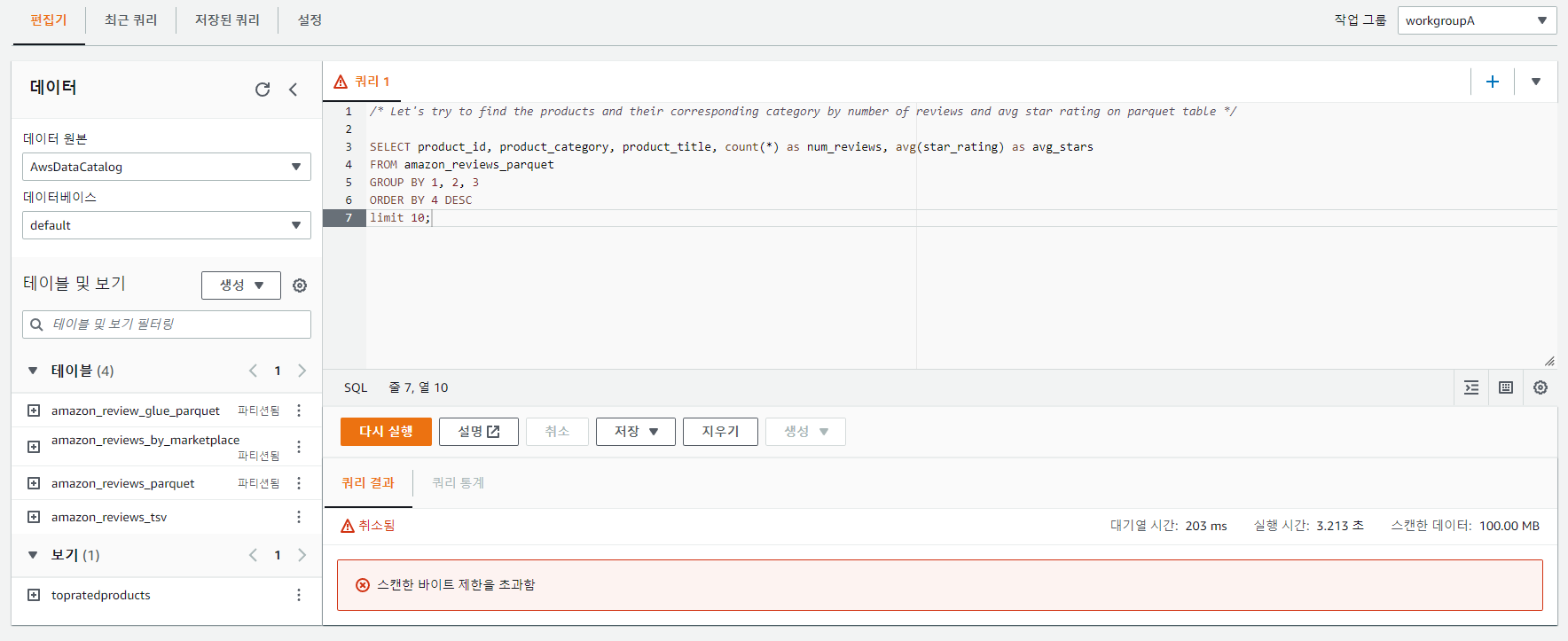
쿼리를 실행해보면 실행 불가!
실행했던 쿼리문이다..
/* Let's try to find the products and their corresponding category by number of reviews and avg star rating on parquet table */
SELECT product_id, product_category, product_title, count(*) as num_reviews, avg(star_rating) as avg_stars
FROM amazon_reviews_parquet
GROUP BY 1, 2, 3
ORDER BY 4 DESC
limit 10;
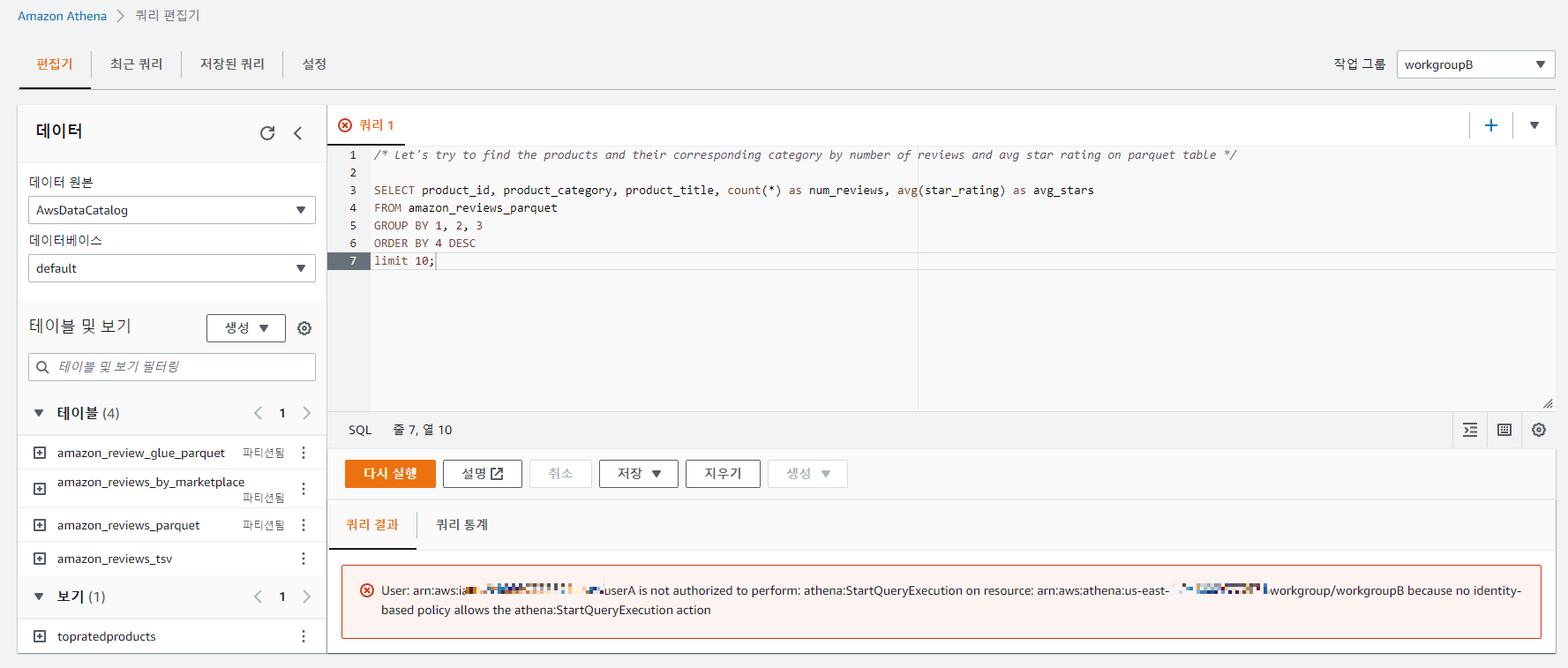
다음으로 workgroupB로 전환하고 userA가 workgroupB에서 동일한 쿼리를 실행할 수 있는지 확인해보자.
저번 포스팅에 이어서 Glue까지 사용을 해보자. 사용 전에 Glue가 뭔지 부터 확인하자.
AWS Glue
분석, 기계 학습 및 애플리케이션 개발을 위해 데이터를 쉽게 탐색, 준비, 조합할 수 있도록 지원하는 서버리스 데이터 통합 서비스
데이터 통합: 해당 개발을 위해 데이터를 준비하고 결합하는 프로세스
데이터 검색 및 추출
데이터 강화, 정리, 정규화 및 결합
데이터베이스, 데이터 웨어하우스 및 데이터 레이크에 데이터 로드 및 구성 등
기능
Data Catalog: 모든 데이터 자산을 위한 영구 메타데이터 스토어
모든 AWS 데이터 세트에서 검색: 자동으로 통계를 계산하고 파티션을 등록, 데이터 변경 사항 파악
Crawlers: 소스/대상 스토어에 연결해 우선순위가 지정된 Classifiers을 거치면서 데이터의 스키마 결정, 메타 데이터 생성
Stream schema registries: Apache Avro 스키마를 사용해 스트리밍 데이터의 변화를 검증하고 제어
Data Integration and ETL(Extract / Transform / Load)
Studio Job Notebooks: Studio에서 최소한으로 설정할 수 있는 서버리스 노트북
Interactive Sessions: 데이터 통합 작업 개발을 간소화, 엔지니어와 대화식으로 데이터 탐색, 준비
ETL 파이프라인 구축: 여러 개의 작업을 병렬로 시작하거나 작업 간에 종속성을 지정
Studio: 분산 처리를 위한 확정성이 뛰어난 ETL 작업 가능, 에디터에서 ETL 프로세스를 정의하면 Glue가 자동으로 코드 생성
등등...
Glue DataBrew: 시각적 데이터 준비 도구(사전 빌드된 250개 이상의 변환 구성 중 선택해서 코드 없이 가능)
솔직히 뭐라고 하는지 모르겠다.. 직접 써보는게 답!
Crawler로 실습을 진행해보자.
Glue로 테이블 만들기
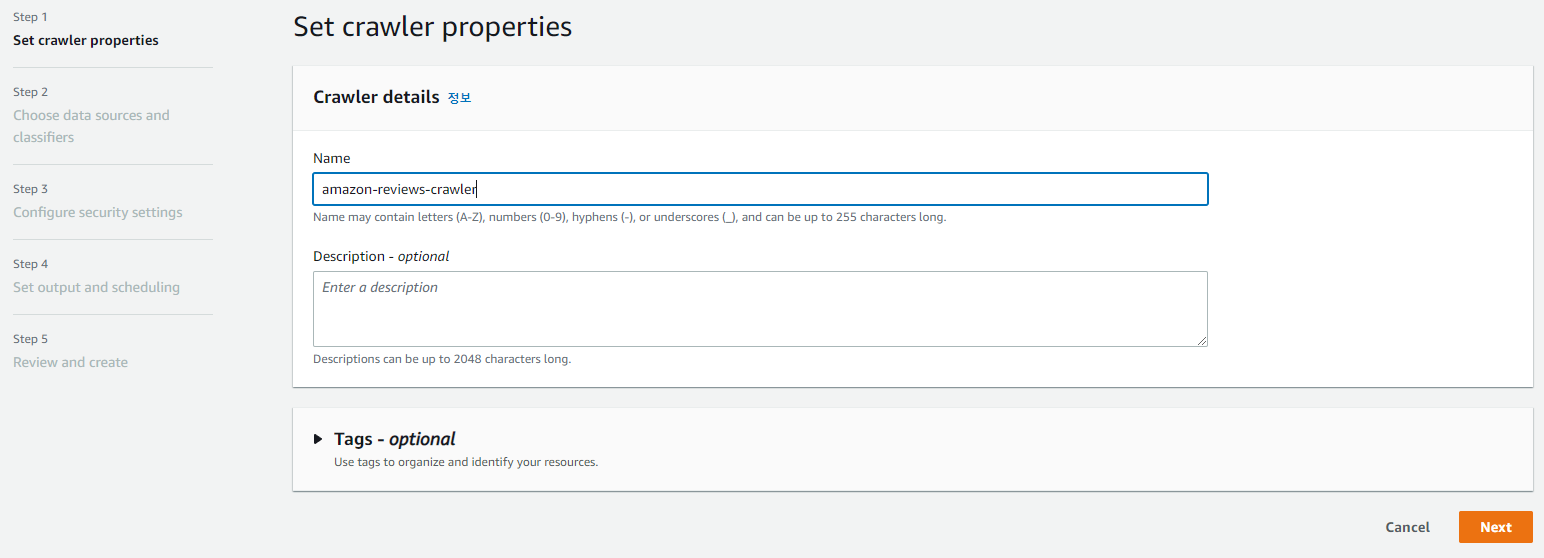
크롤러를 생성해주자.
데이터 스토어는 저번 포스팅 때 가져왔었던 데이터셋이 위치한 버킷으로 지정할 것!
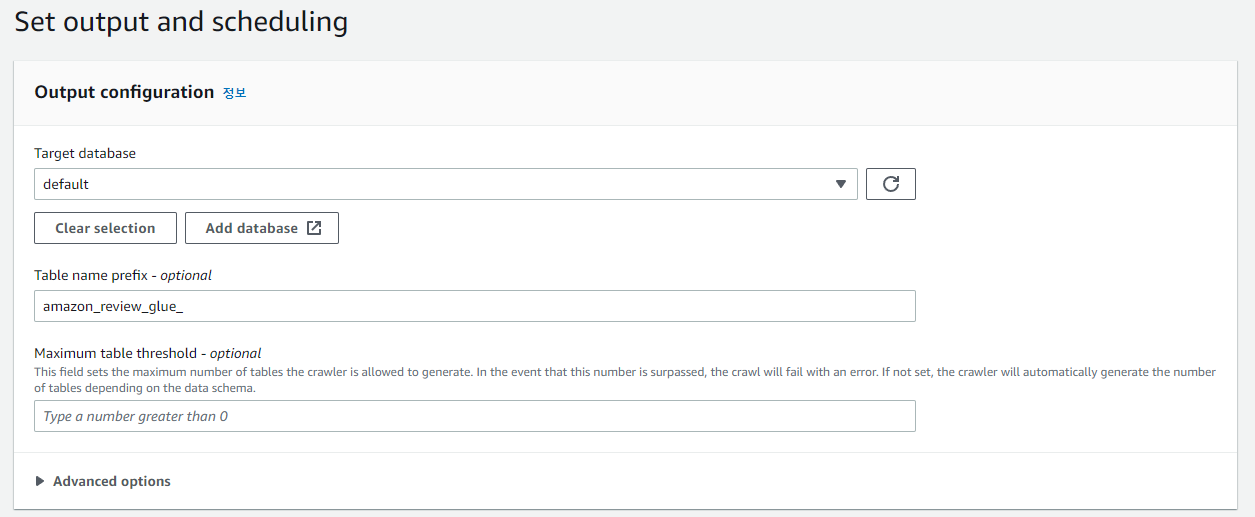
Create new IAM role을 통해 새로 생성하고 지정해준다. 타겟 DB까지 정해주면 끝!
크롤러를 돌려주자(생성된 크롤러 선택 후 Run 버튼 클릭)
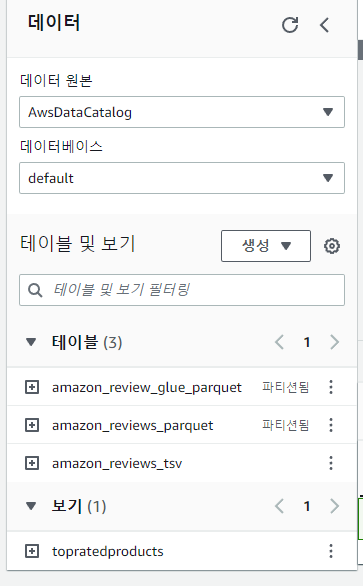
Glue → Tables에 들어가면 테이블이 하나 더 추가된 것을 볼 수 있다.
Athena로 돌아가 다음 쿼리를 실행해 데이터를 확인해보자.
select * from amazon_review_glue_parquet limit 10;
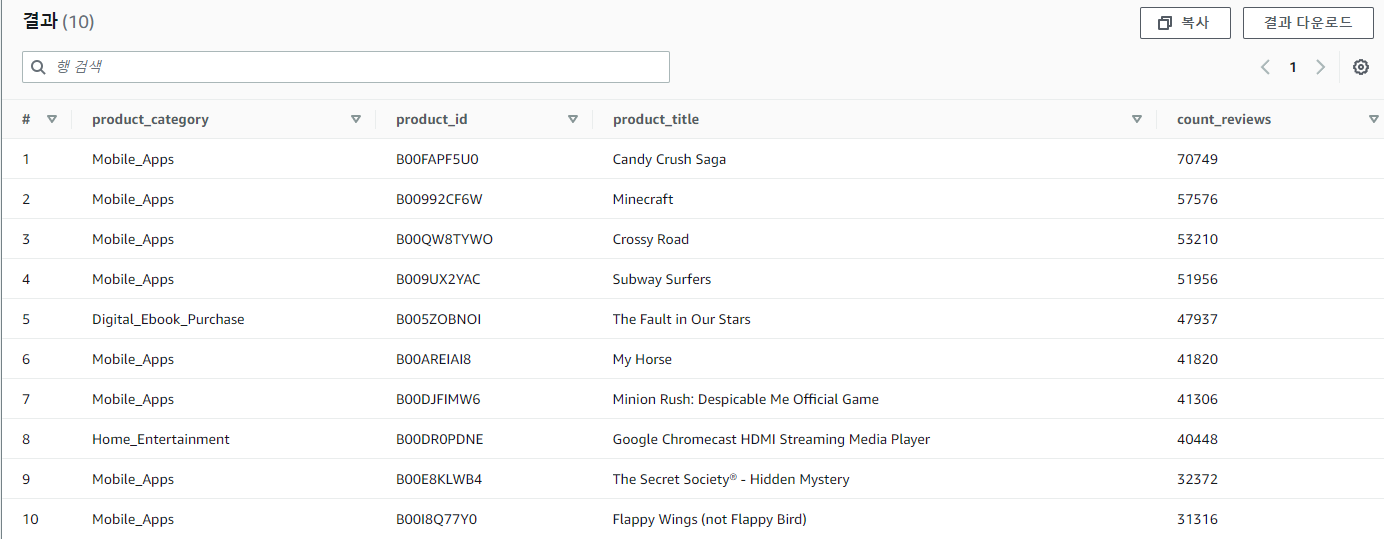
Views 만들기
다시 Athena로 돌아왔다.(Athena의 view는 물리적 테이블이 아닌 논리적 테이블!)
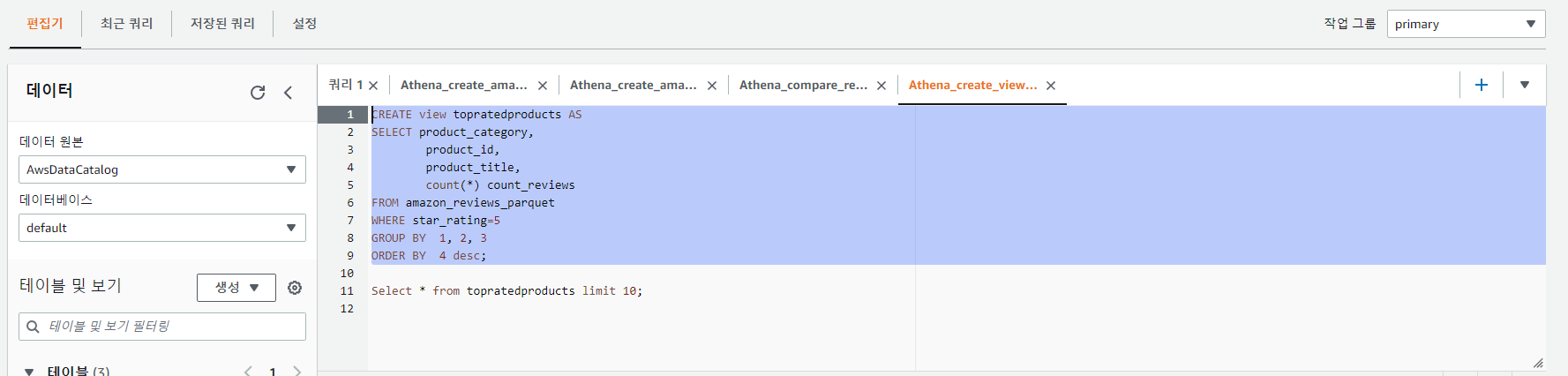
저장된 쿼리에서 Athena_create_view_top_rated를 클릭한다.
위 이미지 처럼 선택 후 실행한다. 아래와 같이 보기에 추가된 것을 확인할 수 있다.
두번째 쿼리를 선택한 뒤 실행해 등급별로 상위 10개 제품을 확인해보자.
결과 확인(S3 버킷)
S3에서 athena-workshop-<account-id> 로 시작하는 버킷을 찾아 들어가면 처음엔 비어있던 버킷이 Athena에서 돌렸던 쿼리문을 기준으로 폴더들이 생성되어 있는 것을 볼 수 있고, Athena_compare_reviews 접두사 중 하나를 찾아보면 쿼리 ID와 함께 저장된 결과를 볼 수 있음.
❗ 그래서 결과적으로 Glue Crawler가 무슨 역할을 했냐...? ❗
크롤러 작동 방식:
데이터를 분류하여 raw data의 포맷, 스키마 및 관련 속성 결정 / 데이터를 테이블 혹은 파티션으로 분류 / 메타데이터를 Data Catalog에 작성
# Purpose: Creates Athena Workgroups, Named Queries, IAM Users via AWS CloudFormation #=============================================================================== AWSTemplateFormatVersion: "2010-09-09" Description: | Athena Immersion Day - Creates Athena Workgroups, Named Queries, IAM Users
/* Next we will load the partitions for this table */ MSCK REPAIR TABLE amazon_reviews_parquet;
/* Check the partitions */ SHOW PARTITIONS amazon_reviews_parquet;
qryamazonreviewstsv: Type: AWS::Athena::NamedQuery Properties: Database: "default" Description: "Reviews Ratings table amazon_reviews_tsv" Name: "Athena_compare_reviews" QueryString: | /* Let's try to find the products and their corresponding category by number of reviews and avg star rating */ SELECT product_id, product_category, product_title, count(*) as num_reviews, avg(star_rating) as avg_stars FROM amazon_reviews_tsv GROUP BY 1, 2, 3 ORDER BY 4 DESC limit 10;
/* Let's try to find the products and their corresponding category by number of reviews and avg star rating on parquet table */ SELECT product_id, product_category, product_title, count(*) as num_reviews, avg(star_rating) as avg_stars FROM amazon_reviews_parquet GROUP BY 1, 2, 3 ORDER BY 4 DESC limit 10;
/* Let's try to find the products by number of reviews and avg star rating in Mobile_Apps category */ SELECT product_id, product_title, count(*) as num_reviews, avg(star_rating) as avg_stars FROM amazon_reviews_tsv where product_category='Mobile_Apps' GROUP BY 1, 2 ORDER BY 3 DESC limit 10;
/* Let's try to find the products by number of reviews and avg star rating in Mobile_Apps category */ SELECT product_id, product_title, count(*) as num_reviews, avg(star_rating) as avg_stars FROM amazon_reviews_parquet where product_category='Mobile_Apps' GROUP BY 1, 2 ORDER BY 3 DESC limit 10;
TopReviewedStarRatedProductsv: Type: AWS::Athena::NamedQuery Properties: Database: "default" Description: "Create View TopRatedProducts" Name: "Athena_create_view_top_rated" QueryString: | CREATE view topratedproducts AS SELECT product_category, product_id, product_title, count(*) count_reviews FROM amazon_reviews_parquet WHERE star_rating=5 GROUP BY 1, 2, 3 ORDER BY 4 desc;
Select * from topratedproducts limit 10;
ctas: Type: AWS::Athena::NamedQuery Properties: Database: "default" Description: "CTAS Amazon Reviews by Marketplace" Name: "Athena_ctas_reviews" QueryString: | CREATE TABLE amazon_reviews_by_marketplace WITH ( format='PARQUET', parquet_compression = 'SNAPPY', partitioned_by = ARRAY['marketplace', 'year'], external_location = 's3://<<Athena-WorkShop-Bucket>>/athena-ctas-insert-into/') AS SELECT customer_id, review_id, product_id, product_parent, product_title, product_category, star_rating, helpful_votes, total_votes, verified_purchase, review_headline, review_body, review_date, marketplace, year(review_date) AS year FROM amazon_reviews_tsv WHERE "$path" LIKE '%tsv.gz';
/* Let's try to find the products and their corresponding category by number of reviews and avg star rating for US marketplace in year 2015 */
SELECT product_id, product_category, product_title, count(*) AS num_reviews, avg(star_rating) AS avg_stars FROM amazon_reviews_by_marketplace WHERE marketplace='US' AND year=2015 GROUP BY 1, 2, 3 ORDER BY 4 DESC limit 10;
comparereviews: Type: AWS::Athena::NamedQuery Properties: Database: "default" Description: "Compare query performance" Name: "Athena_compare_reviews_marketplace" QueryString: | SELECT product_id, COUNT(*) FROM amazon_reviews_by_marketplace WHERE marketplace='US' AND year = 2013 GROUP BY 1 ORDER BY 2 DESC LIMIT 10;
SELECT product_id, COUNT(*) FROM amazon_reviews_parquet WHERE marketplace='US' AND year = 2013 GROUP BY 1 ORDER BY 2 DESC LIMIT 10;
SELECT product_id, COUNT(*) FROM amazon_reviews_tsv WHERE marketplace='US' AND extract(year from review_date) = 2013 GROUP BY 1 ORDER BY 2 DESC LIMIT 10;
flights: Type: AWS::Athena::NamedQuery Properties: Database: "default" Description: "Top 10 routes delayed by more than 1 hour" Name: "Athena_flight_delay_60" QueryString: | SELECT origin, dest, count(*) as delays FROM flight_delay_parquet WHERE depdelayminutes > 60 GROUP BY origin, dest ORDER BY 3 DESC LIMIT 10;
ConsolePassword: Description: AWS Secrets URL to find the generated password for User A and User B Value: !Sub 'https://console.aws.amazon.com/secretsmanager/home?region=${AWS::Region}#/secret?name=/athenaworkshopuser/password'
스택의 리소스나 이벤트를 확인해보면 생성 결과 → 쿼리문 파일들 + Athena 작업그룹 + IAM User A/B + S3 버킷 정도?
사실 이번 포스팅에서 User를 나누는 의미는 없다. 나중에 이어서 실습할 내용들에 있어서 필요한 유저들..
쿼리를 하나씩 선택해서 실행해 각 결과를 비교해보자.(스캔한 데이터 양과 소요 시간 차이 확인)
파티셔닝 전의 테이블: amazon_reviews_tsv
평균 리뷰별 상위 10개 제픔모바일 앱 카테고리의 평균 리뷰 기준 상위 10개 제품
파티셔닝 후의 테이블: amazon_reviews_parquet
평균 리뷰별 상위 10개 제품모바일 앱 카테고리의 평균 리뷰 기준 상위 10개 제품
확실히 파티셔닝 후의 테이블의 성능이 뛰어나다는 것을 확인할 수 있다.
기본적인 SQL문(Select From 뭐시기... 이런 것)들은 알고 있는데..
파티셔닝 관련한 명령은 알지 못해서.. 간단히 정리해본다.
파티션을 사용하는 테이블을 생성하려면 CREATE TABLE 문에 PARTITIONED BY 절을 사용
기본 문법:
CREATE EXTERNAL TABLE users (
first string,
last string,
username string
)
PARTITIONED BY (id string)
STORED AS parquet
LOCATION 's3://DOC-EXAMPLE-BUCKET/folder/'
테이블을 생성하고 쿼리를 위해 파티션에 데이터를 로드하는 명령
(참고로 parquet(파켓)은 Apache Hadoop 에코 시스템의 오픈소스 열 지향 데이터 저장 형식)
이후에 Hive 스타일 파티션의 경우 MSCK REPAIR TABLE을 실행(지금 했던 방식)
아니라면 ALTER TABLE ADD PARTITON을 사용해 파티션을 수동으로 추가
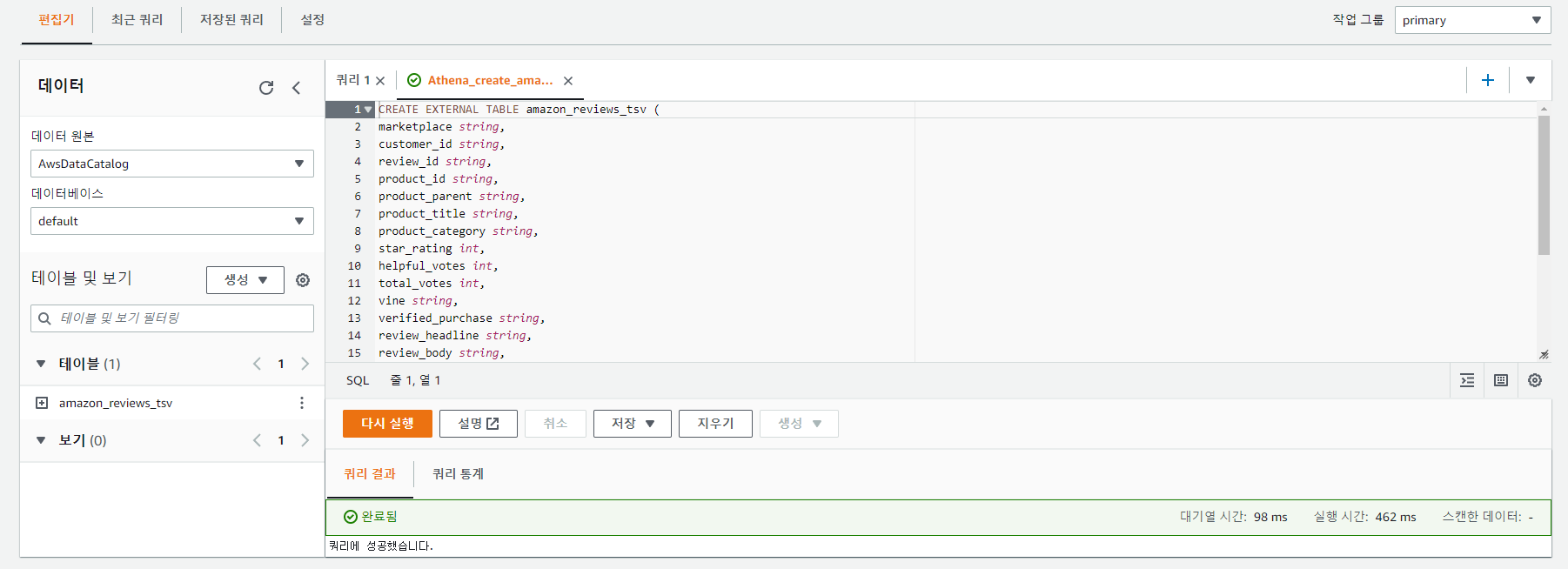
CREATE EXTERNAL TABLE amazon_reviews_parquet(
marketplace string,
customer_id string,
review_id string,
product_id string,
product_parent string,
product_title string,
star_rating int,
helpful_votes int,
total_votes int,
vine string,
verified_purchase string,
review_headline string,
review_body string,
review_date bigint,
year int)
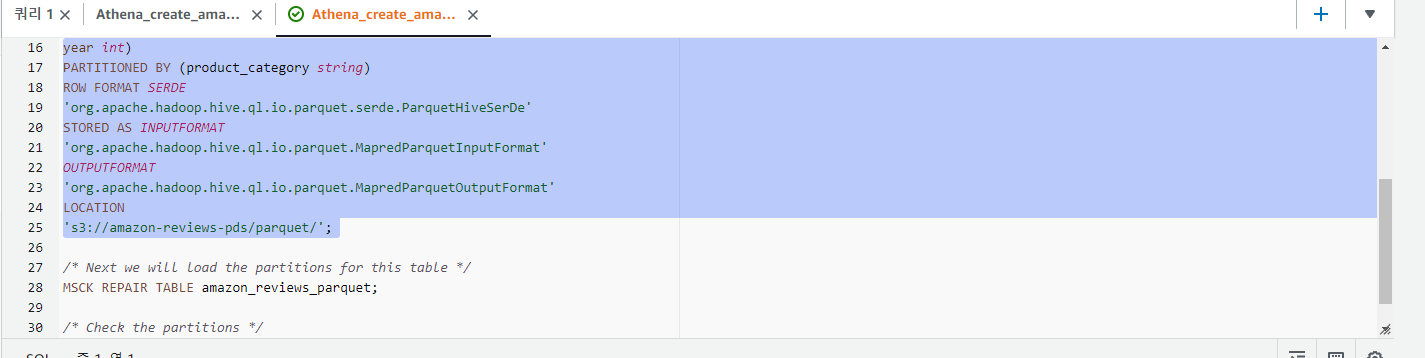
PARTITIONED BY (product_category string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
's3://amazon-reviews-pds/parquet/';
/* Next we will load the partitions for this table */
MSCK REPAIR TABLE amazon_reviews_parquet;
/* Check the partitions */
SHOW PARTITIONS amazon_reviews_parquet;