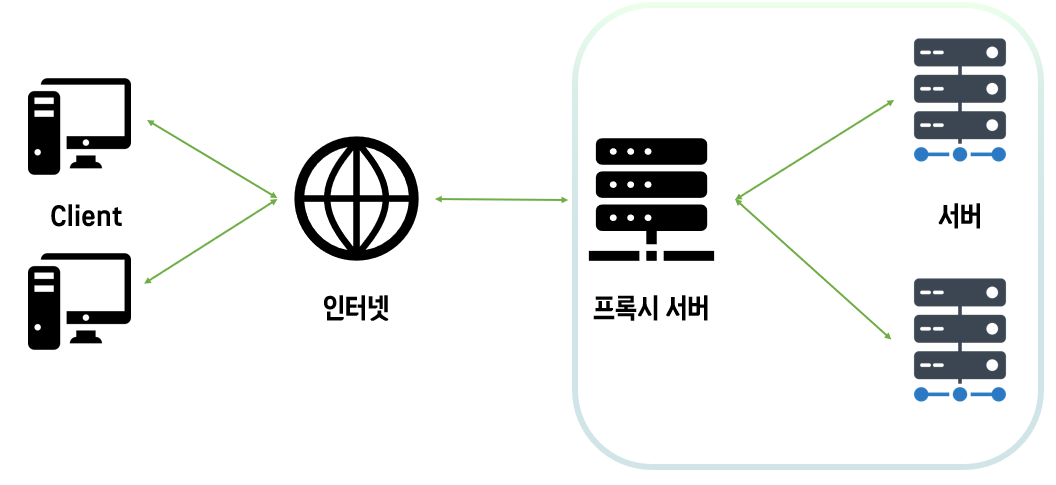
일단은 Proxy가 정확하게 뭔지 잘 몰라서 해당 내용 부터 살펴 본다면,
Proxy
'대리', '대신' 의 뜻, 주로 보안 상의 문제를 방지하기 위해 직접 통신하지 않고 중계자를 거친다는 개념
여기서의 중계자가 'Proxy Server'
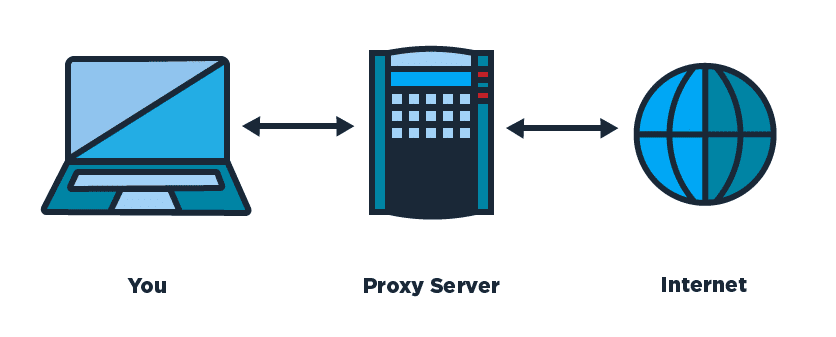
클라이언트가 프록시 서버에 요청한 내용을 서버에 캐시로 저장해두면, 전송 시간을 절약할 수 있고, 특정 사이트는 접근 불가능하도록 제한을 걸 수도 있다. → Forward Proxy
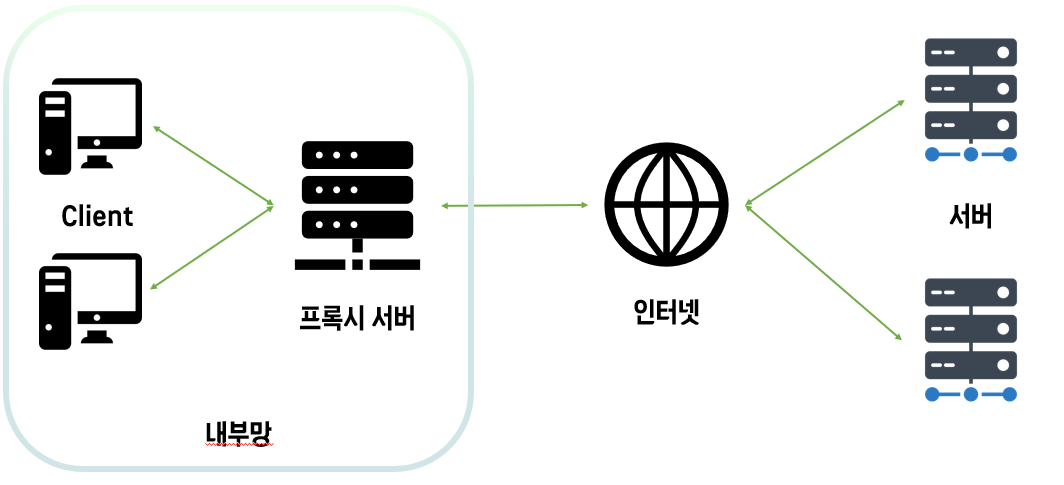
클라이언트가 바로 서버에 데이터를 요청해 받을 수 있지만, DB가 노출될 수 있는 위험이 존재한다. 중간에 프록시 서버를 두고 내부망을 보호하는 역할을 할 수도 있다. → Reverse Proxy
RDS Proxy
- Connection Pooling
- 커넥션을 열고 닫으며 많은 커넥션을 동시에 열린 상태로 유지하는 데 관련된 오버헤드를 줄이는 최적화 기능
- connection multiplexing: 커넥션 재사용(하나의 DB 연결을 사용해 한 트랜잭션에 대한 모든 작업 수행)
- 데이터베이스 장애조치(failover)와 같은 오류 시나리오 동안 애플리케이션 가용성 개선
- 장애 조치 동안 애플리케이션 연결 유지
- TLS/SSL 및 IAM을 포함한 RDS 보안 기능을 사용해 애플리케이션 코드에서 연결에 대한 자격 증명 불필요
- AWS Secrets Manager와 통합되어 하드 코딩할 필요가 없음(DB 자격 증명을 중앙에서 관리)
- CloudWatch 메트릭 및 로깅
- 주요 메트릭: ClientConnections, QueryRequests, DatabaseConnections
- 로그 그룹 내에서 모니터링: /aws/rds/proxy/[proxy-name]
VPC 생성
cloudformation으로 생성
AWSTemplateFormatVersion: "2010-09-09"
Description: 'Cloudformation template to create VPC for workshop (Optimize Serverless Application on AWS)'
Resources:
VPC:
Type: AWS::EC2::VPC
Properties:
CidrBlock: 10.0.0.0/16
EnableDnsSupport: true
EnableDnsHostnames: true
Tags:
- Key: Name
Value: serverless-app
InternetGateway:
Type: AWS::EC2::InternetGateway
Properties:
Tags:
- Key: Name
Value: serverless-app-igw
InternetGatewayAttachment:
Type: AWS::EC2::VPCGatewayAttachment
Properties:
InternetGatewayId: !Ref InternetGateway
VpcId: !Ref VPC
PrivateSubnet1:
Type: AWS::EC2::Subnet
Properties:
VpcId: !Ref VPC
AvailabilityZone: ap-northeast-2a
CidrBlock: 10.0.1.0/24
MapPublicIpOnLaunch: false
Tags:
- Key: Name
Value: lambda-subnet-a
PrivateSubnet2:
Type: AWS::EC2::Subnet
Properties:
VpcId: !Ref VPC
AvailabilityZone: ap-northeast-2c
CidrBlock: 10.0.2.0/24
MapPublicIpOnLaunch: false
Tags:
- Key: Name
Value: lambda-subnet-c
PrivateSubnet3:
Type: AWS::EC2::Subnet
Properties:
VpcId: !Ref VPC
AvailabilityZone: ap-northeast-2a
CidrBlock: 10.0.10.0/24
MapPublicIpOnLaunch: false
Tags:
- Key: Name
Value: rds-subnet-a
PrivateSubnet4:
Type: AWS::EC2::Subnet
Properties:
VpcId: !Ref VPC
AvailabilityZone: ap-northeast-2c
CidrBlock: 10.0.20.0/24
MapPublicIpOnLaunch: false
Tags:
- Key: Name
Value: rds-subnet-c
PrivateSubnet5:
Type: AWS::EC2::Subnet
Properties:
VpcId: !Ref VPC
AvailabilityZone: ap-northeast-2a
CidrBlock: 10.0.100.0/24
MapPublicIpOnLaunch: false
Tags:
- Key: Name
Value: secret-subnet-a
PrivateSubnet6:
Type: AWS::EC2::Subnet
Properties:
VpcId: !Ref VPC
AvailabilityZone: ap-northeast-2c
CidrBlock: 10.0.200.0/24
MapPublicIpOnLaunch: false
Tags:
- Key: Name
Value: secret-subnet-c
PublicSubnet1:
Type: AWS::EC2::Subnet
Properties:
VpcId: !Ref VPC
AvailabilityZone: ap-northeast-2a
CidrBlock: 10.0.0.0/24
MapPublicIpOnLaunch: true
Tags:
- Key: Name
Value: cloud9-subnet-a
PublicRouteTable:
Type: AWS::EC2::RouteTable
Properties:
VpcId: !Ref VPC
Tags:
- Key: Name
Value: serverless-app-routes
DefaultPublicRoute:
Type: AWS::EC2::Route
DependsOn: InternetGatewayAttachment
Properties:
RouteTableId: !Ref PublicRouteTable
DestinationCidrBlock: 0.0.0.0/0
GatewayId: !Ref InternetGateway
PublicSubnet1RouteTableAssociation:
Type: AWS::EC2::SubnetRouteTableAssociation
Properties:
RouteTableId: !Ref PublicRouteTable
SubnetId: !Ref PublicSubnet1
Outputs:
VPC:
Description: serverless-app-vpc
Value: !Ref VPC
보안 그룹 생성
- lambda-sg
- rds-sg: MySQL / lambda-sg
RDS 생성
- 서브넷 그룹 생성: 10.0.10.0/24(a az), 10.0.20.0/24 (c az)
- DB 생성:
- MySQL 5.7.33 버전
- db.m5.large / gp2 20GB
- VPC쪽 위에서 생성했던 것들..
Lambda 생성
- python 3.8
- VPC 활성화: 10.0.1.0/24, 10.0.2.0/24 / lambda-sg
- 코드
import json
import pymysql
def lambda_handler(event, context):
db = pymysql.connect(
host='YOUR RDS ENDPOINT',
user='YOUR DATABASE MASTER USERNAME',
password='YOUR MASTER PASSWORD'
)
cursor = db.cursor()
cursor.execute("select now()")
result = cursor.fetchone()
db.commit()
db.close()
return {
'statusCode': 200,
'body': json.dumps(result[0].isoformat())
}현재는 db 연결 테스트를 위한 작업으로 로그인이 하드코딩으로 이루어져 있다. 이후에 RDS Proxy를 통해 변경할 예정
Lambda Layer 추가
pymysql 패키지를 추가해줘야...
그 후에 lambda test를 돌려보자("statusCode: 200"이면 성공한 것)
API Gateway 구성
- REST API / 새 api
- 리소스 - 작업 / GET 추가
- lambda func: 위에서 설정했던 lambda 이름
- 리소스 - 작업 / API 배포: 새 스테이지 - 이름
URL 클릭해보면 아까 lambda에서 테스트 했던 결과와 똑같이 나옴..
lambda 함수 개요로 다시 돌아가보면 api gateway가 트리거로 잡혀있다.

이제 RDS Proxy를 적용해보자!
AWS Secrets Manager 구성
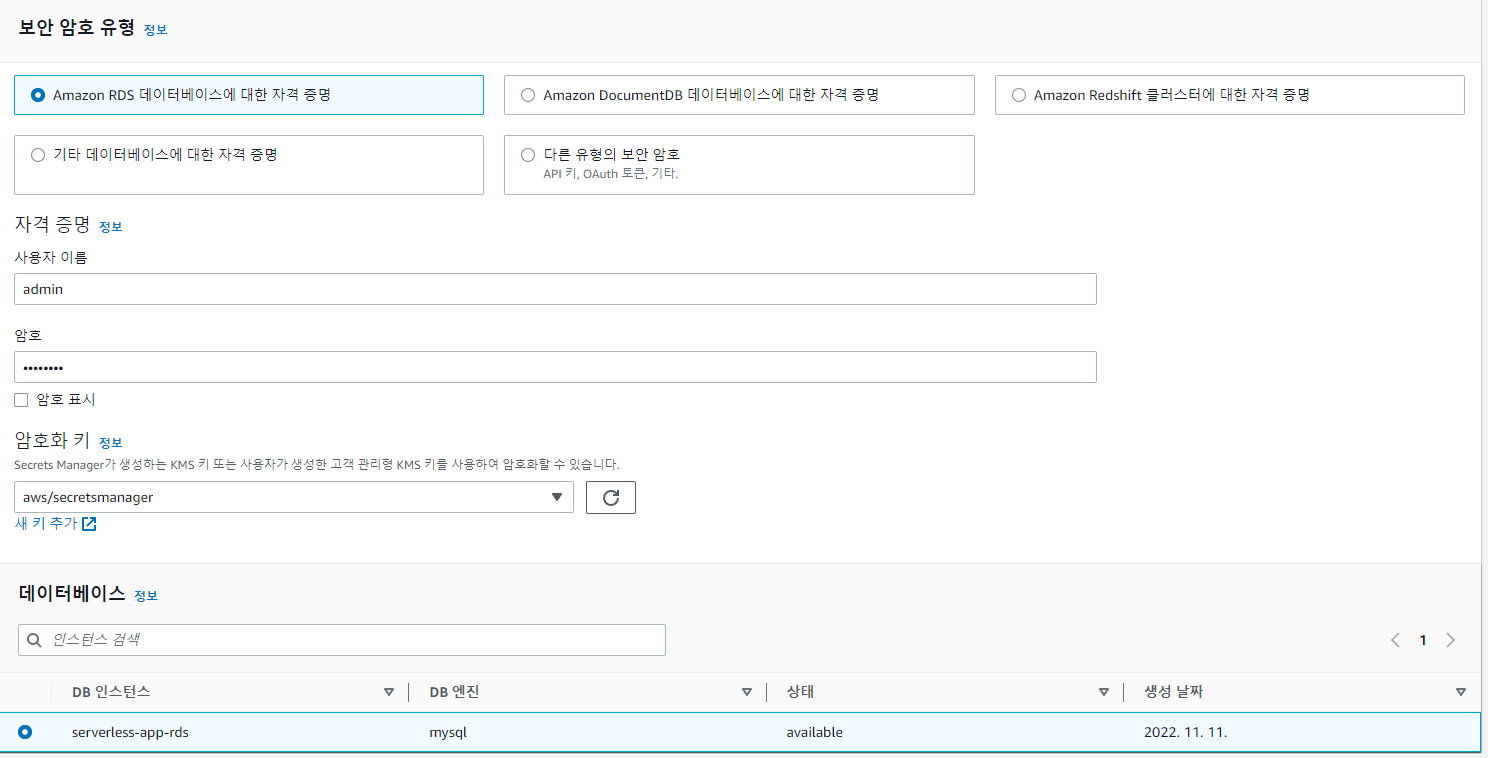
암호는 RDS 생성 시 넣어줬던 비밀번호로 설정해주면 된다.
자동 교체의 경우는 비활성화로 진행한다.(테스트 용이니까)
Secrets Manager를 사용하면 기본적으로 퍼블릭 통신을 통해 DB 크리덴셜을 가져오지만, VPC Endpoints를 사용하면 프라이빗 엔드포인트를 통해 VPC 내의 리소스가 직접 액세스 할 수 있음!
VPC로 돌아가 생성되었던 VPC 선택 후
- 작업 → DNS 호스트 이름 편집 활성화
VPC Endpoints 설정에는 보안 그룹이 필요하다. Secrets Manager의 경우 Lambda에 접근 가능해야함..
- 보안그룹: secret-sg / HTTPS - lambda-sg
VPC Endpoints 설정
- AWS 서비스 - 위에서 설정했던 Secrets Manager
- VPC: 위에서 생성했던 대로.. 서브넷 (secret-subnet-a/c), 보안그룹: secret-sg
RDS Proxy 구성
서버리스에서 사실 RDS를 사용하기엔 어려움이 있다.
(서버리스 아키텍처를 기반으로 구축된 애플리케이션은 DB에 다수의 커넥션을 만들어 max_connections 옵션을 초과하는 에러가 발생하거나 빠른 속도로 DB 커넥션을 여닫아 과도하게 메모리와 컴퓨팅 리소스를 소진할 수도 있음.)
RDS Proxy를 사용할 경우 애플리케이션과 DB 사이의 연결을 풀링하고 공유가 가능해 조금이나마 도움이 될 수 있음!
따라서 lambda와 rds 커넥션을 하고 싶다면 Proxy를 활용해라
- MySQL
- 위에서 생성했던 rds, secrets manager, 서브넷은 rds-subnet-a/c 확인 후 나머지 제거
- 보안그룹 rds-sg 추가
Lambda 함수 변경
구성 → 권한 → IAM Role 수정
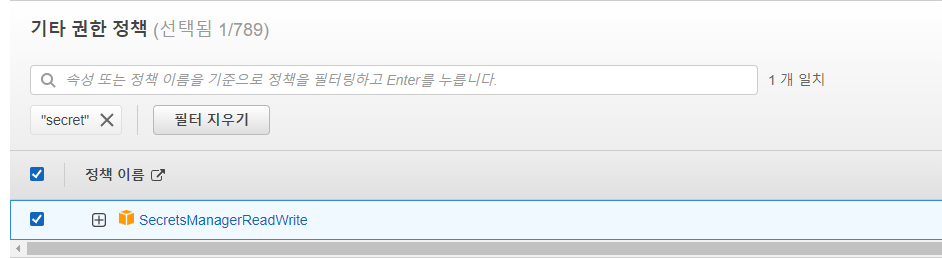
해당 Secrets Manager에 대한 권한을 부여한다.
그 후에 코드 변경
import json
import pymysql
import boto3
import base64
import time
from botocore.exceptions import ClientError
secret_name = "serverless-app-rds-secret"
region_name = "ap-northeast-2"
def get_secret():
session = boto3.session.Session()
client = session.client(
service_name = 'secretsmanager',
region_name = region_name
)
get_secret_value_response = client.get_secret_value(
SecretId=secret_name
)
if 'SecretString' in get_secret_value_response:
secret = get_secret_value_response['SecretString']
return secret
else:
decoded_binary_secret = base64.b64decode(get_secret_value_response['SecretBinary'])
return decoded_binary_secret
def lambda_handler(event, context):
secret = get_secret()
json_secret = json.loads(secret)
db = pymysql.connect(
host = 'YOUR RDS PROXY ENDPOINT',
user = json_secret['username'],
password = json_secret['password']
)
cursor = db.cursor()
cursor.execute("select now()")
result = cursor.fetchone()
db.commit()
return {
'statusCode': 200,
'body': json.dumps(result[0].isoformat())
}해당 RDS Proxy 엔드포인트 쪽만 변경
이제 다 구성했으니 제대로 작동하는지 확인해보자.
- API Gateway로 이동해 아까 생성했던 스테이지로 가서 Invoke URL 후 호출해보자
- 연결하는데 시간이 초과한다는 에러가 나면 lambda 함수 제한 시간을 늘려주자..ㅠ
- 이래서 서버리스는 서버리스끼리 사용하라는 듯..
- 아니면 구성을 다시 한번 되집어 보자...(중간에 엇갈렸었음;;)
부하테스트
사실상 메인 테스트, 내가 하고 싶은 테스트를 진행해볼까 한다!
Cloud9 - 부하테스트 도구 Locust 구성
- c5.24xlarge
- VPC 변경- cloud9-subnet
pip3 install locust
locust -v
locustfile.py 파일 생성 후 코드 넣어주기(단순히 GET을 통한 테스트)
import time
from locust import HttpUser, task, between
class QuickstartUser(HttpUser):
@task
def hello_world(self):
self.client.get("/")
터미널에 다음 명령어 입력해 실행하기
locust
web interface에서 편하게 진행하기 위해 ec2로 간다.
해당 cloud9 인스턴스에서 보안그룹을 변경해준다.
- Custom TCP 8089 / Anywhere
http://public ip:8089를 입력해 Locust web interface에 접속한다.

- Number of users: 동시에 실행하는 최대의 Locust user
- Spawn rate: 초당 생성하는 Locust user
- Host: 부하를 발생할 호스트 - 오늘의 테스트는 API Gateway Endpoint
1차 부하테스트
- Number of users: 10000 / Spawn rate: 500 / Host: API Gateway Invoke URL
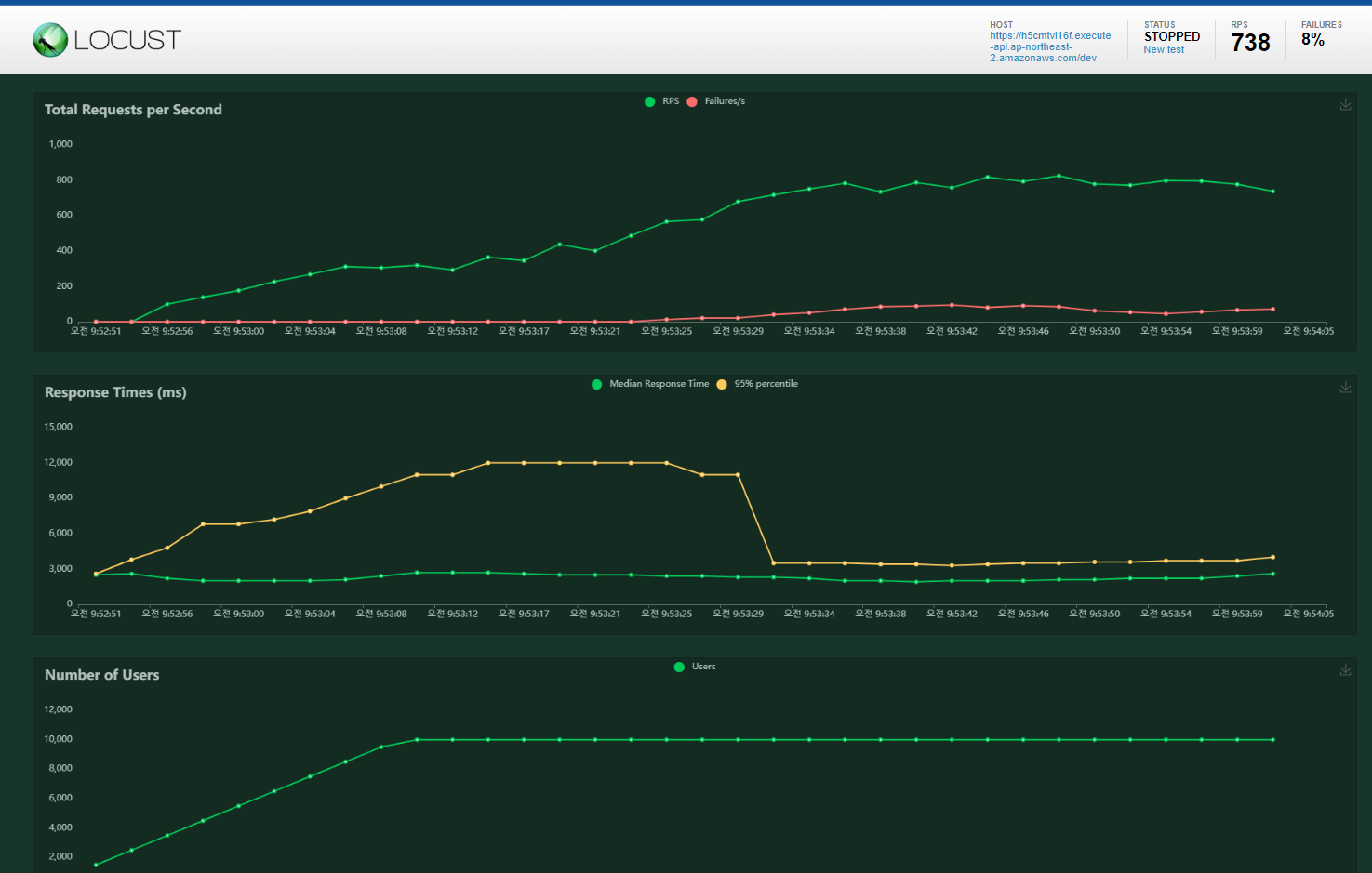
Lambda 모니터링으로 돌아와 확인해보면, Burst Limit에 도달한 뒤 1분당 500씩 Concurrent executions이 증가하는 것을 볼 수 있다. 최초 스케일링 전 스로틀 발생했다가 Lambda가 스케일링 되면서 해소되는 것을 확인 할 수 있다.
(but, AWS에서 제공하는 기본 Concurrent executions 제한이 1000이여서 스케일링에 대한 부분 확인이 어려울 수 있음)
Lambda 코드 최적화
Lambda의 스로틀링을 회피해야 성능이 좋아질 듯?
그 방법에는
1) Lambda provisioned concurrency를 통해 지정한 갯수 만큼의 실행 환경을 구성해 두는 것
2) 동시성의 최소화를 위해 Lambda 함수의 실행 시간을 최적화 하는 것(얘는 모범 사례 중 하나)
지금 현재의 코드는 lambda_handler() 내에서 get_secret()을 통해 DB 크리덴셜 정보를 읽고 DB와 연결을 맺는 구조로 되어 있음. 이는 Lambda 가 호출될 때마다 고정된 값인 DB 크리덴셜을 읽고 새롭게 DB와 연결하는 구조라 비효율적..
이를 최적화 한다. 의 의미는 실행환경의 재사용성을 극대화 하는 것
현재 Lambda test를 해보면 실행시간이 약 700ms이다.

import json
import pymysql
import boto3
import base64
secret_name = "serverless-app-rds-secret"
region_name = "ap-northeast-2"
def get_secret():
session = boto3.session.Session()
client = session.client(
service_name = 'secretsmanager',
region_name = region_name
)
get_secret_value_response = client.get_secret_value(
SecretId=secret_name
)
if 'SecretString' in get_secret_value_response:
secret = get_secret_value_response['SecretString']
return secret
else:
decoded_binary_secret = base64.b64decode(get_secret_value_response['SecretBinary'])
return decoded_binary_secret
secret = get_secret()
json_secret = json.loads(secret)
db = pymysql.connect(
host = 'YOUR RDS PROXY ENDPOINT',
user = json_secret['username'],
password = json_secret['password']
)
cursor = db.cursor()
def lambda_handler(event, context):
cursor.execute("select now()")
result = cursor.fetchone()
db.commit()
return {
'statusCode': 200,
'body': json.dumps(result[0].isoformat())
}위 코드와 같이 최적화 후에 테스트 해보면,

실행시간이 약 7ms로 최적화 된 것을 확인할 수 있음!!!
2차 부하테스트
Newtest 클릭!
위의 설정과 같게 돌려보자.
1차 테스트와 비교해보면 코드 최적화 이후 줄어든 Throttles와 Concurrent executions, Duration 등을 확인할 수 있다.
(Lambda 모니터링에서)
❗ 여기에 덧붙일만한 건 X-Ray로 모니터링 추적하는 기능 추가 정도...? 이는 다른 포스팅에 있으니.. 확인하시오!! ❗
'Cloud > AWS' 카테고리의 다른 글
| [AWS] Step Functions (0) | 2022.11.18 |
|---|---|
| [AWS] Spot Fleet (0) | 2022.11.16 |
| [AWS] EC2 인스턴스 자동 중지 및 시작 (0) | 2022.11.13 |
| [AWS] GPU 인스턴스 Spot Fleet (0) | 2022.11.12 |
| [AWS] GPU 인스턴스 유형(EC2) (0) | 2022.11.12 |