( 참고: https://amazon-dynamodb-labs.com/hands-on-labs.html )
실습편

CloudFormation을 통한 환경 구성
퍼블릭 서브넷 1개 / 프라이빗 서브넷 3개 / 퍼블릭 서브넷에 배포된 AWS Cloud 9 환경
AWSTemplateFormatVersion: "2010-09-09"
# Copyright 2020 Amazon.com, Inc. or its affiliates. All Rights Reserved.
#
# Permission is hereby granted, free of charge, to any person obtaining a copy of this
# software and associated documentation files (the "Software"), to deal in the Software
# without restriction, including without limitation the rights to use, copy, modify,
# merge, publish, distribute, sublicense, and/or sell copies of the Software, and to
# permit persons to whom the Software is furnished to do so.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,
# INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A
# PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT
# HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
# OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE
# SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
Description: >
This template builds a VPC with 1 public and 3 private subnets.
Parameters:
vpccidr:
Type: String
MinLength: 9
MaxLength: 18
AllowedPattern: "(\\d{1,3})\\.(\\d{1,3})\\.(\\d{1,3})\\.(\\d{1,3})/(\\d{1,2})"
ConstraintDescription: Must be a valid CIDR range in the form x.x.x.x/16
Default: 10.20.0.0/16
AppPublicCIDRA:
Type: String
MinLength: 9
MaxLength: 18
AllowedPattern: "(\\d{1,3})\\.(\\d{1,3})\\.(\\d{1,3})\\.(\\d{1,3})/(\\d{1,2})"
ConstraintDescription: Must be a valid CIDR range in the form x.x.x.x/22
Default: 10.20.1.0/24
AppPrivateCIDRA:
Type: String
MinLength: 9
MaxLength: 18
AllowedPattern: "(\\d{1,3})\\.(\\d{1,3})\\.(\\d{1,3})\\.(\\d{1,3})/(\\d{1,2})"
ConstraintDescription: Must be a valid CIDR range in the form x.x.x.x/22
Default: 10.20.2.0/24
AppPrivateCIDRB:
Type: String
MinLength: 9
MaxLength: 18
AllowedPattern: "(\\d{1,3})\\.(\\d{1,3})\\.(\\d{1,3})\\.(\\d{1,3})/(\\d{1,2})"
ConstraintDescription: Must be a valid CIDR range in the form x.x.x.x/22
Default: 10.20.3.0/24
AppPrivateCIDRC:
Type: String
MinLength: 9
MaxLength: 18
AllowedPattern: "(\\d{1,3})\\.(\\d{1,3})\\.(\\d{1,3})\\.(\\d{1,3})/(\\d{1,2})"
ConstraintDescription: Must be a valid CIDR range in the form x.x.x.x/22
Default: 10.20.4.0/24
IdeType:
Type: String
Default: "t3.medium"
ProjectTag:
Type: String
Default: "dynamodb-labs"
Resources:
VPC:
Type: "AWS::EC2::VPC"
Properties:
CidrBlock: !Ref vpccidr
EnableDnsHostnames: 'true'
EnableDnsSupport: 'true'
Tags:
-
Key: Project
Value: !Ref ProjectTag
-
Key: Name
Value: !Join ["", [!Ref ProjectTag, "-VPC"]]
IGW:
Type: "AWS::EC2::InternetGateway"
Properties:
Tags:
-
Key: Project
Value: !Ref ProjectTag
-
Key: Name
Value: !Join ["", [!Ref ProjectTag, "-IGW"]]
GatewayAttach:
Type: "AWS::EC2::VPCGatewayAttachment"
Properties:
InternetGatewayId: !Ref IGW
VpcId: !Ref VPC
SubnetPublicA:
Type: "AWS::EC2::Subnet"
Properties:
AvailabilityZone: !Select [0, !GetAZs ]
CidrBlock: !Ref AppPublicCIDRA
MapPublicIpOnLaunch: true
VpcId: !Ref VPC
Tags:
-
Key: Project
Value: !Ref ProjectTag
-
Key: Name
Value: !Join ["", [!Ref ProjectTag, "-Subnet-PublicA"]]
SubnetPrivateA:
Type: "AWS::EC2::Subnet"
Properties:
AvailabilityZone: !Select [0, !GetAZs ]
CidrBlock: !Ref AppPrivateCIDRA
MapPublicIpOnLaunch: false
VpcId: !Ref VPC
Tags:
-
Key: Project
Value: !Ref ProjectTag
-
Key: Name
Value: !Join ["", [!Ref ProjectTag, "-Subnet-PrivateA"]]
SubnetPrivateB:
Type: "AWS::EC2::Subnet"
Properties:
AvailabilityZone: !Select [1, !GetAZs ]
CidrBlock: !Ref AppPrivateCIDRB
MapPublicIpOnLaunch: false
VpcId: !Ref VPC
Tags:
-
Key: Project
Value: !Ref ProjectTag
-
Key: Name
Value: !Join ["", [!Ref ProjectTag, "-Subnet-PrivateB"]]
SubnetPrivateC:
Type: "AWS::EC2::Subnet"
Properties:
AvailabilityZone: !Select [2, !GetAZs ]
CidrBlock: !Ref AppPrivateCIDRC
MapPublicIpOnLaunch: false
VpcId: !Ref VPC
Tags:
-
Key: Project
Value: !Ref ProjectTag
-
Key: Name
Value: !Join ["", [!Ref ProjectTag, "-Subnet-PrivateC"]]
SubnetRouteTableAssociatePublicA: # Associates the subnet with a route table - passed via import
DependsOn: SubnetPublicA
Type: "AWS::EC2::SubnetRouteTableAssociation"
Properties:
RouteTableId: !Ref RouteTablePublic
SubnetId: !Ref SubnetPublicA
SubnetRouteTableAssociatePrivateA: # Associates the subnet with a route table - passed via parameter
DependsOn: SubnetPrivateA
Type: "AWS::EC2::SubnetRouteTableAssociation"
Properties:
RouteTableId: !Ref RouteTablePrivateA
SubnetId: !Ref SubnetPrivateA # Associates the subnet with a route table - passed via parameter
SubnetRouteTableAssociatePrivateB: # Associates the subnet with a route table - passed via parameter
DependsOn: SubnetPrivateB
Type: "AWS::EC2::SubnetRouteTableAssociation"
Properties:
RouteTableId: !Ref RouteTablePrivateB
SubnetId: !Ref SubnetPrivateB # Associates the subnet with a route table - passed via parameter
SubnetRouteTableAssociatePrivateC: # Associates the subnet with a route table - passed via parameter
DependsOn: SubnetPrivateC
Type: "AWS::EC2::SubnetRouteTableAssociation"
Properties:
RouteTableId: !Ref RouteTablePrivateC
SubnetId: !Ref SubnetPrivateC # Associates the subnet with a route table - passed via parameter
RouteDefaultPublic:
Type: "AWS::EC2::Route"
DependsOn: GatewayAttach
Properties:
DestinationCidrBlock: 0.0.0.0/0
GatewayId: !Ref IGW
RouteTableId: !Ref RouteTablePublic
RouteTablePublic:
Type: "AWS::EC2::RouteTable"
Properties:
VpcId: !Ref VPC
RouteDefaultPrivateA:
Type: "AWS::EC2::Route"
Properties:
DestinationCidrBlock: 0.0.0.0/0
NatGatewayId: !Ref NatGatewayA
RouteTableId: !Ref RouteTablePrivateA
RouteDefaultPrivateB:
Type: "AWS::EC2::Route"
Properties:
DestinationCidrBlock: 0.0.0.0/0
NatGatewayId: !Ref NatGatewayA
RouteTableId: !Ref RouteTablePrivateB
RouteDefaultPrivateC:
Type: "AWS::EC2::Route"
Properties:
DestinationCidrBlock: 0.0.0.0/0
NatGatewayId: !Ref NatGatewayA
RouteTableId: !Ref RouteTablePrivateC
RouteTablePrivateA:
Type: "AWS::EC2::RouteTable"
Properties:
VpcId: !Ref VPC
RouteTablePrivateB:
Type: "AWS::EC2::RouteTable"
Properties:
VpcId: !Ref VPC
RouteTablePrivateC:
Type: "AWS::EC2::RouteTable"
Properties:
VpcId: !Ref VPC
EIPNatGWA:
DependsOn: GatewayAttach
Type: "AWS::EC2::EIP"
Properties:
Domain: vpc
NatGatewayA:
Type: "AWS::EC2::NatGateway"
Properties:
AllocationId: !GetAtt EIPNatGWA.AllocationId
SubnetId: !Ref SubnetPublicA
Tags:
-
Key: Project
Value: !Ref ProjectTag
-
Key: Name
Value: !Join ["", [!Ref ProjectTag, "-NatGWA"]]
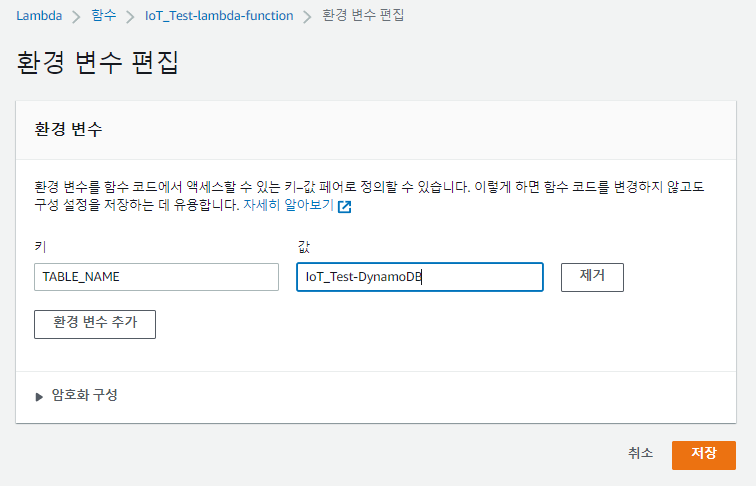
DynamoDBLabsIDE:
Type: AWS::Cloud9::EnvironmentEC2
Properties:
Description: "Cloud 9 IDE"
InstanceType: !Ref IdeType
SubnetId: !Ref SubnetPublicA
Tags:
-
Key: Project
Value: !Ref ProjectTag
-
Key: ProjectName
Value: !Join ["", [!Ref ProjectTag, "-Ide"]]
Outputs:
VpcId:
Description: VPC ID
Value: !Ref VPC
SubnetIdPublicA:
Description: Subnet ID for first public subnet
Value: !Ref SubnetPublicA
SubnetIdPrivateA:
Description: Subnet ID for first private subnet
Value: !Ref SubnetPrivateA
SubnetIdPrivateB:
Description: Subnet ID for second private subnet
Value: !Ref SubnetPrivateB
SubnetIdPrivateC:
Description: Subnet ID for third private subnet
Value: !Ref SubnetPrivateC
RouteTableIdPrivateC:
Value: !Ref RouteTablePrivateC
RouteTableIdPrivateB:
Value: !Ref RouteTablePrivateB
RouteTableIdPrivateA:
Value: !Ref RouteTablePrivateA
Cloud9 콘솔
aws sts get-caller-identity위의 명령어로 AWS 자격 증명이 올바르게 구성되었는지 확인
aws dynamodb create-table \
--table-name ProductCatalog \
--attribute-definitions \
AttributeName=Id,AttributeType=N \
--key-schema \
AttributeName=Id,KeyType=HASH \
--provisioned-throughput \
ReadCapacityUnits=10,WriteCapacityUnits=5
aws dynamodb create-table \
--table-name Forum \
--attribute-definitions \
AttributeName=Name,AttributeType=S \
--key-schema \
AttributeName=Name,KeyType=HASH \
--provisioned-throughput \
ReadCapacityUnits=10,WriteCapacityUnits=5
aws dynamodb create-table \
--table-name Thread \
--attribute-definitions \
AttributeName=ForumName,AttributeType=S \
AttributeName=Subject,AttributeType=S \
--key-schema \
AttributeName=ForumName,KeyType=HASH \
AttributeName=Subject,KeyType=RANGE \
--provisioned-throughput \
ReadCapacityUnits=10,WriteCapacityUnits=5
aws dynamodb create-table \
--table-name Reply \
--attribute-definitions \
AttributeName=Id,AttributeType=S \
AttributeName=ReplyDateTime,AttributeType=S \
--key-schema \
AttributeName=Id,KeyType=HASH \
AttributeName=ReplyDateTime,KeyType=RANGE \
--provisioned-throughput \
ReadCapacityUnits=10,WriteCapacityUnits=5
aws dynamodb wait table-exists --table-name ProductCatalog && \
aws dynamodb wait table-exists --table-name Reply && \
aws dynamodb wait table-exists --table-name Forum && \
aws dynamodb wait table-exists --table-name Threadcreate-table 명령어를 통해 테이블을 생성하고 wait 명령어를 활용해 테이블을 하나씩 생성하도록...
https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/SampleData.html
wget https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/samples/sampledata.zip
unzip sampledata.zip샘플 데이터를 다운로드하고 압축을 푼다.
aws dynamodb batch-write-item --request-items file://ProductCatalog.json
aws dynamodb batch-write-item --request-items file://Forum.json
aws dynamodb batch-write-item --request-items file://Thread.json
aws dynamodb batch-write-item --request-items file://Reply.jsonbatch-write-item CLI를 사용해 샘플 데이터 로드
CLI로 DynamoDB 탐색
aws dynamodb scan --table-name ProductCatalogscan api 를 사용해 테이블을 스캔할 수 있다. 하지만 DynamoDB에서 데이터를 가져올 때 가장 느리고 비싼 방법!
현재는 아이템이 몇 개 없으니까 테스트 가능하다.
(CLI의 데이터 입력 및 출력은 JSON 형식을 활용한다.)
aws dynamodb get-item \
--table-name ProductCatalog \
--key '{"Id":{"N":"101"}}'하나의 아이템을 가져오기 위해선 GetItem api 활용! DynamoDB에서 데이터를 가져오는 가장 빠르고 저렴한 방법이다.
aws dynamodb get-item \
--table-name ProductCatalog \
--key '{"Id":{"N":"101"}}' \
--consistent-read \
--projection-expression "ProductCategory, Price, Title" \
--return-consumed-capacity TOTAL읽기 일관성에 관한 옵션에는
--consistent-read: 강력한 일관된 읽기를 원함(쓰기 작업 결과가 다 반영이 된 후에 읽음)
--projection-expression: 요청에서 특정 속성만 반환되도록 지정
--return-consume-capacity: 요청에 의해 소비된 용량 알려줌
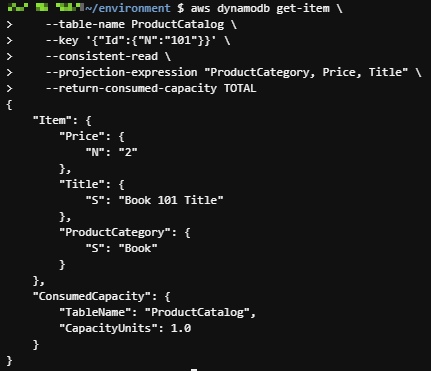
위의 결과는 --consistent-read 옵션을 사용했을 때, 1.0 RCU를 사용(항목이 4KB 미만)
해당 옵션을 제거하면 최종적으로 일관된 읽기가 절반의 용량을 사용함!!(0.5 RCU)
이제부턴 쿼리를 사용해 아이템을 읽어올 것!
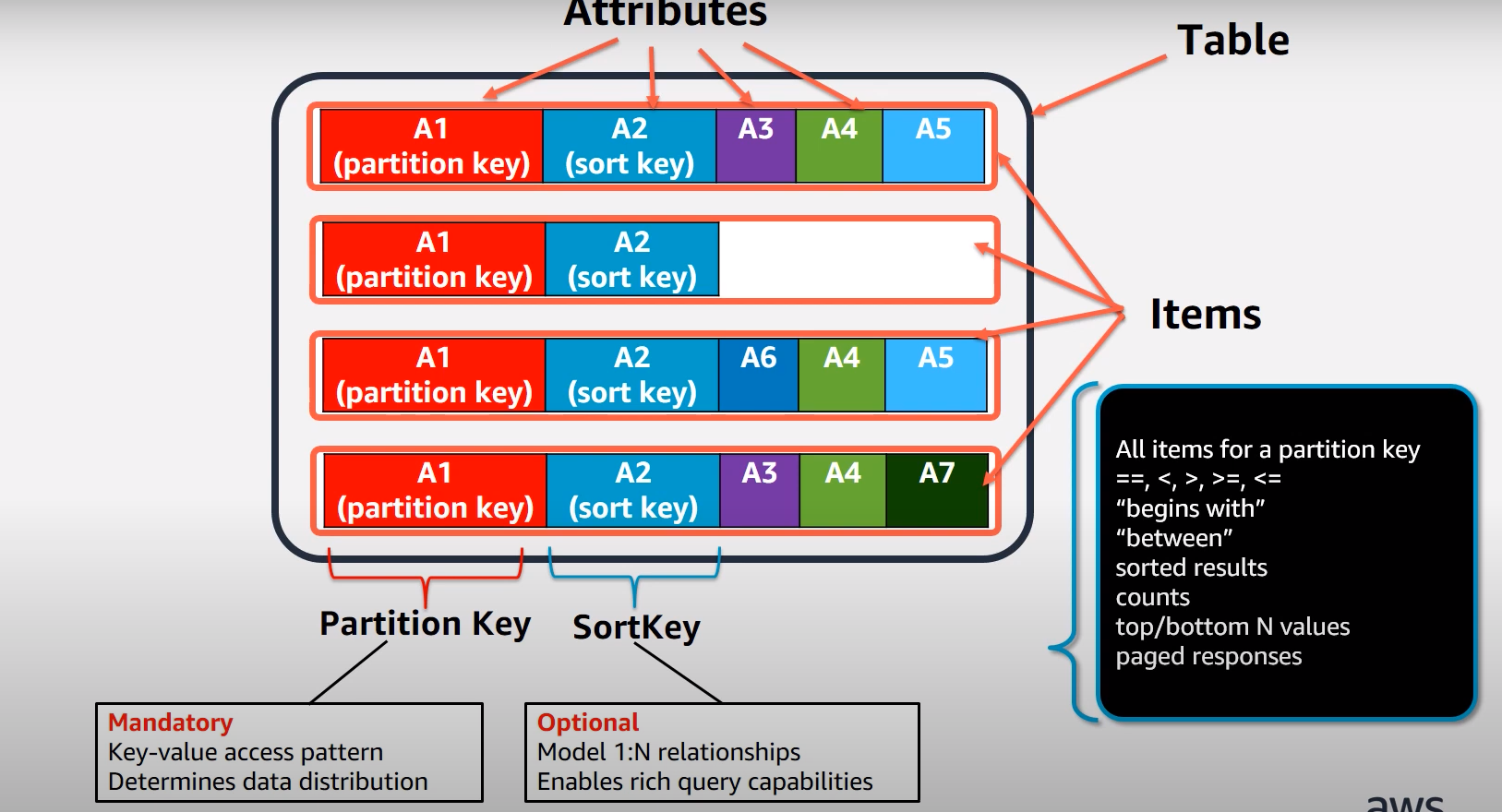
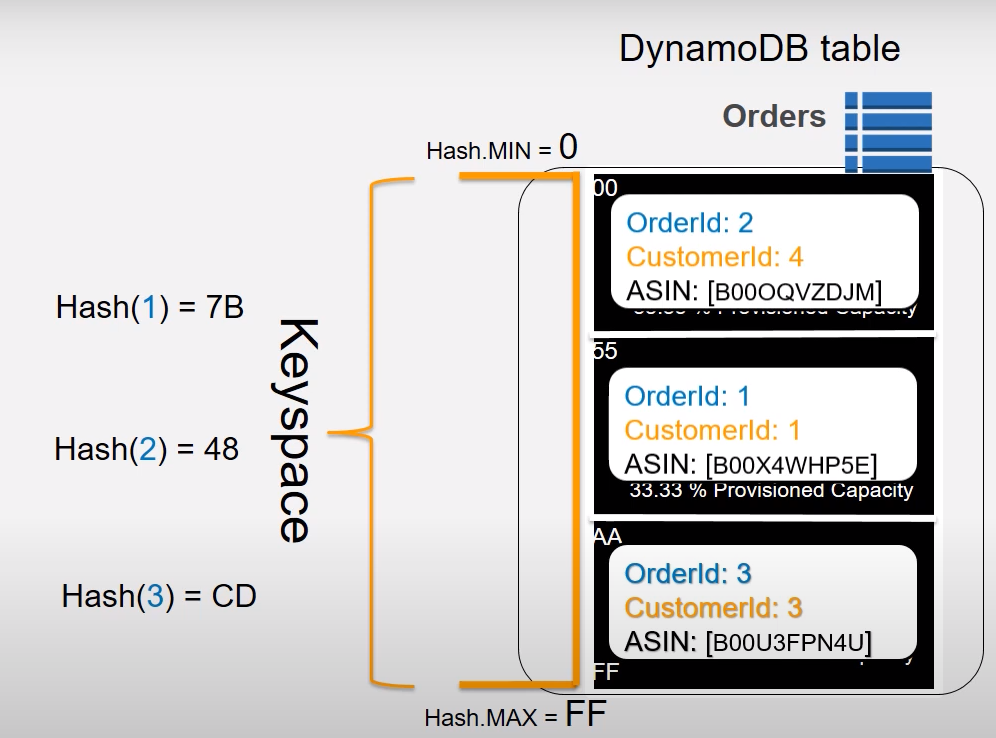
Item Collections은 partition key를 공유하는 collection group.
DynamoDB에서 "query"는 Item collection의 전체 또는 일부를 읽는 특정 의미이다.(RDBMS와 다름)
aws dynamodb scan --table-name Reply
Replay 테이블에 데이터에는 Thread 테이블의 항목을 참조하는 Id Attribute가 있음
쿼리 CLI를 통해 Thread 1의 아이템만 가져오자.
aws dynamodb query \
--table-name Reply \
--key-condition-expression 'Id = :Id' \
--expression-attribute-values '{
":Id" : {"S": "Amazon DynamoDB#DynamoDB Thread 1"}
}' \
--return-consumed-capacity TOTAL
Replay 테이블의 정렬 키는 타임스탬프다. 정렬 키 조건을 추가해 특정 시간 이후에 게시된 스레드의 응답만 가져오자.
aws dynamodb query \
--table-name Reply \
--key-condition-expression 'Id = :Id and ReplyDateTime > :ts' \
--expression-attribute-values '{
":Id" : {"S": "Amazon DynamoDB#DynamoDB Thread 1"},
":ts" : {"S": "2015-09-21"}
}' \
--return-consumed-capacity TOTAL
키가 아닌 attribute의 기반으로 결과를 제한하기 위한 필터 표현식을 사용하자.
aws dynamodb query \
--table-name Reply \
--key-condition-expression 'Id = :Id' \
--filter-expression 'PostedBy = :user' \
--expression-attribute-values '{
":Id" : {"S": "Amazon DynamoDB#DynamoDB Thread 1"},
":user" : {"S": "User B"}
}' \
--return-consumed-capacity TOTAL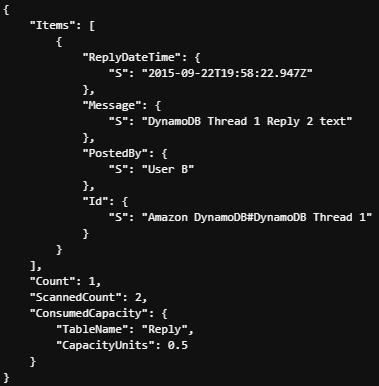
위와 같은 결과를 얻게 되는데 키 조건 표현식이 2개 아이템(ScannedCount)과 일치하고 필터 표현식이 1개 아이템으로 줄였다는 것을 볼 수 있음..
이 밖에도 여러 옵션으로 쿼리 작성 가능하다!
이제는 테이블 스캔 관련 작업을 해보자.
scan api는 단일 아이템 컬렉션이 아닌 전체 테이블을 스캔하려고 하기 때문에 스캔에 대한 필터 표현식을 걸어주는게 좋다.
예) User A가 게시한 답장에서 모든 답글 찾기
aws dynamodb scan \
--table-name Reply \
--filter-expression 'PostedBy = :user' \
--expression-attribute-values '{
":user" : {"S": "User A"}
}' \
--return-consumed-capacity TOTAL
데이터를 스캔할 때 서버 측의 1MB 제한에 도달하거나 지정된 --max-items 매개변수 보다 더 많은 아이템이 남아 있는 경우가 있을 수 있다. 이 경우엔 스캔 응답에 NextToken이 포함되며 이를 후속 스캔 호출에 넣어 중단한 위치에서 선택이 가능하다.
예) 위의 예시에서 --max-items를 2로 걸어보자(위의 응답은 3개 였음..)
aws dynamodb scan \
--table-name Reply \
--filter-expression 'PostedBy = :user' \
--expression-attribute-values '{
":user" : {"S": "User A"}
}' \
--max-items 2 \
--return-consumed-capacity TOTAL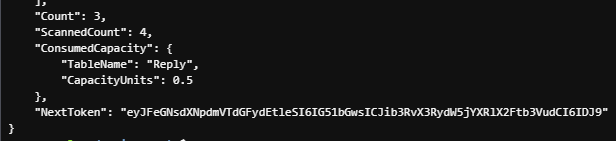
위의 NextToken을 --starting-token 옵션에 포함해 명령하자.
aws dynamodb scan \
--table-name Reply \
--filter-expression 'PostedBy = :user' \
--expression-attribute-values '{
":user" : {"S": "User A"}
}' \
--max-items 2 \
--starting-token eyJFeGNsdXNpdmVTdGFydEtleSI6IG51bGwsICJib3RvX3RydW5jYXRlX2Ftb3VudCI6IDJ9 \
--return-consumed-capacity TOTAL데이터 삽입 관련 (put-item)
aws dynamodb put-item \
--table-name Reply \
--item '{
"Id" : {"S": "Amazon DynamoDB#DynamoDB Thread 2"},
"ReplyDateTime" : {"S": "2021-04-27T17:47:30Z"},
"Message" : {"S": "DynamoDB Thread 2 Reply 3 text"},
"PostedBy" : {"S": "User C"}
}' \
--return-consumed-capacity TOTAL
데이터 업데이트 (update-item)
--condition-expression이 충족되는 경우에만 업데이트 가능!
aws dynamodb update-item \
--table-name Forum \
--key '{
"Name" : {"S": "Amazon DynamoDB"}
}' \
--update-expression "SET Messages = :newMessages" \
--condition-expression "Messages = :oldMessages" \
--expression-attribute-values '{
":oldMessages" : {"N": "4"},
":newMessages" : {"N": "5"}
}' \
--return-consumed-capacity TOTAL
데이터 삭제 (delete-item)
aws dynamodb delete-item \
--table-name Reply \
--key '{
"Id" : {"S": "Amazon DynamoDB#DynamoDB Thread 2"},
"ReplyDateTime" : {"S": "2021-04-27T17:47:30Z"}
}'
Replay 테이블에서 항목을 제거했으니 Forum 관련 메시지 개수 줄여야함!
aws dynamodb update-item \
--table-name Forum \
--key '{
"Name" : {"S": "Amazon DynamoDB"}
}' \
--update-expression "SET Messages = :newMessages" \
--condition-expression "Messages = :oldMessages" \
--expression-attribute-values '{
":oldMessages" : {"N": "5"},
":newMessages" : {"N": "4"}
}' \
--return-consumed-capacity TOTAL이번엔 GSI를 다뤄보자.
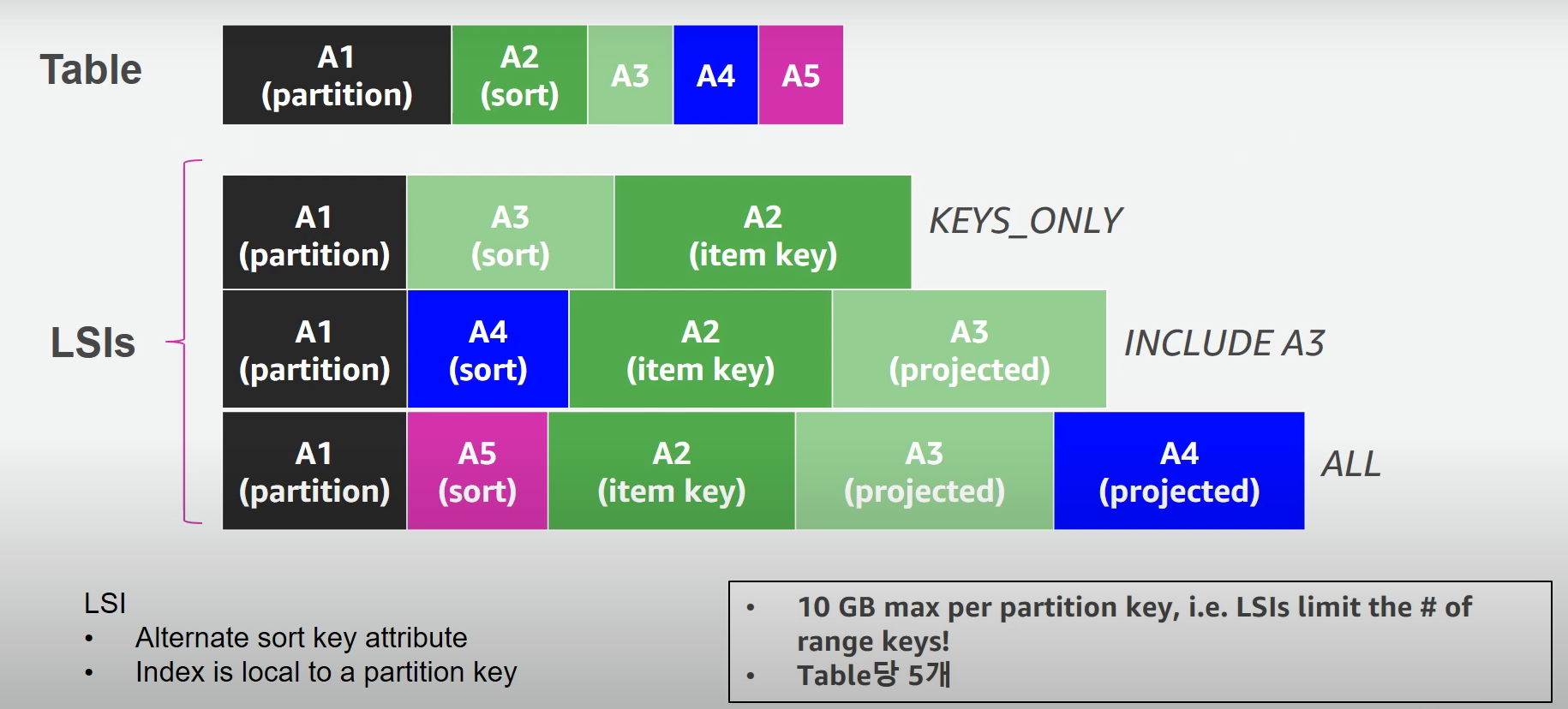
GSI는 테이블에 이미 데이터가 있더라도 언제든 만들고 제거가 가능하다.
예) PostedBy 속성을 파티션(HASH) 키로 사용, ReplyDateTime으로 정렬된 메시지를 정렬(RANGE) 키로 유지하는 PostedBy-ReplyDateTime-gsi 라는 이름의 GSI 생성
aws dynamodb update-table \
--table-name Reply \
--attribute-definitions AttributeName=PostedBy,AttributeType=S AttributeName=ReplyDateTime,AttributeType=S \
--global-secondary-index-updates '[{
"Create":{
"IndexName": "PostedBy-ReplyDateTime-gsi",
"KeySchema": [
{
"AttributeName" : "PostedBy",
"KeyType": "HASH"
},
{
"AttributeName" : "ReplyDateTime",
"KeyType" : "RANGE"
}
],
"ProvisionedThroughput": {
"ReadCapacityUnits": 5, "WriteCapacityUnits": 5
},
"Projection": {
"ProjectionType": "ALL"
}
}
}
]'
DynamoDB가 GSI를 생성하고 테이블의 데이터를 인덱스로 채우는 데 시간이 걸릴 수 있음.
IndexStatus가 Active가 되어야 함!!
aws dynamodb describe-table --table-name Reply | grep IndexStatus
어떤 식으로 사용하게 되냐면...
--index-name query 옵션과 사용하게 됨!
aws dynamodb query \
--table-name Reply \
--key-condition-expression 'PostedBy = :pb' \
--expression-attribute-values '{
":pb" : {"S": "User A"}
}' \
--index-name PostedBy-ReplyDateTime-gsi \
--return-consumed-capacity TOTAL현재는 아이템 수가 적어서 괜찮지만 예를 들어 십만개 이상의 아이템이 있더라도 반환하려는 정확한 아이템을 읽는데만 비용이 든다!
GSI 삭제
aws dynamodb update-table \
--table-name Reply \
--global-secondary-index-updates '[{
"Delete":{
"IndexName": "PostedBy-ReplyDateTime-gsi"
}
}
]'DynamoDB 콘솔 살펴보기
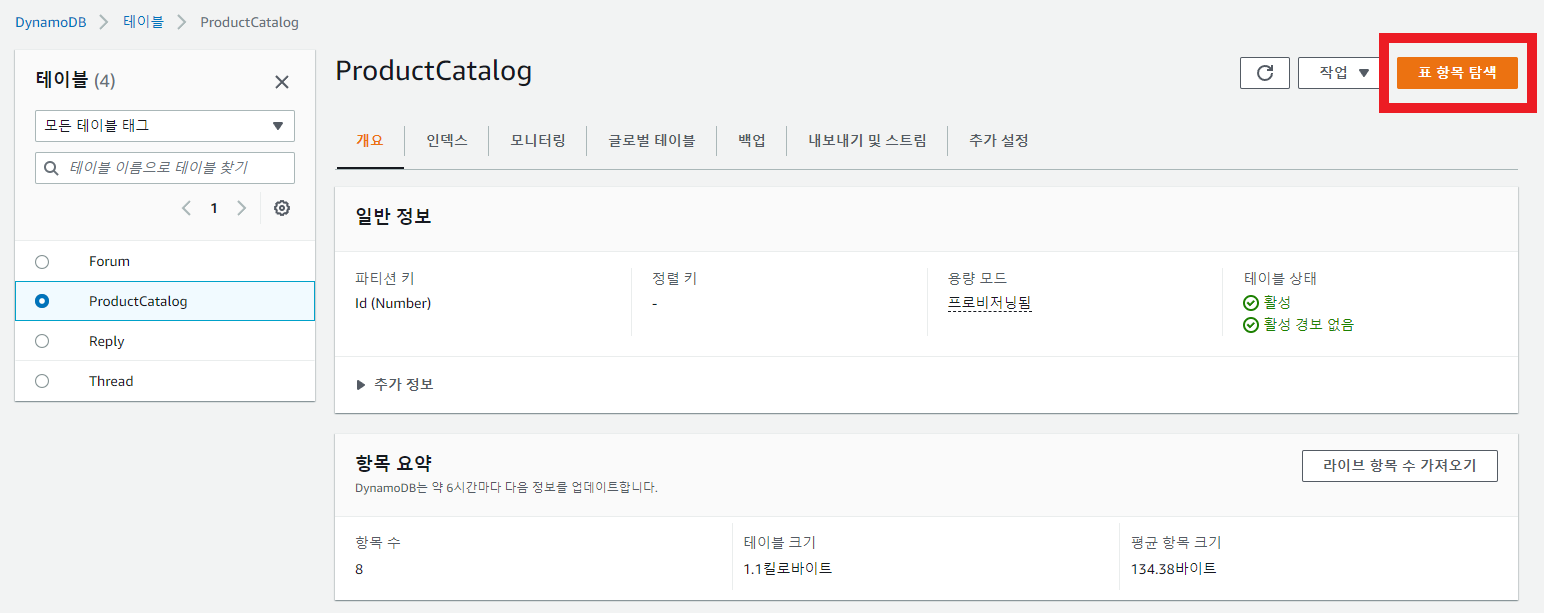
테이블로 들어가 표 항목 탐색을 클릭하면 아이템들을 확인할 수 있다.
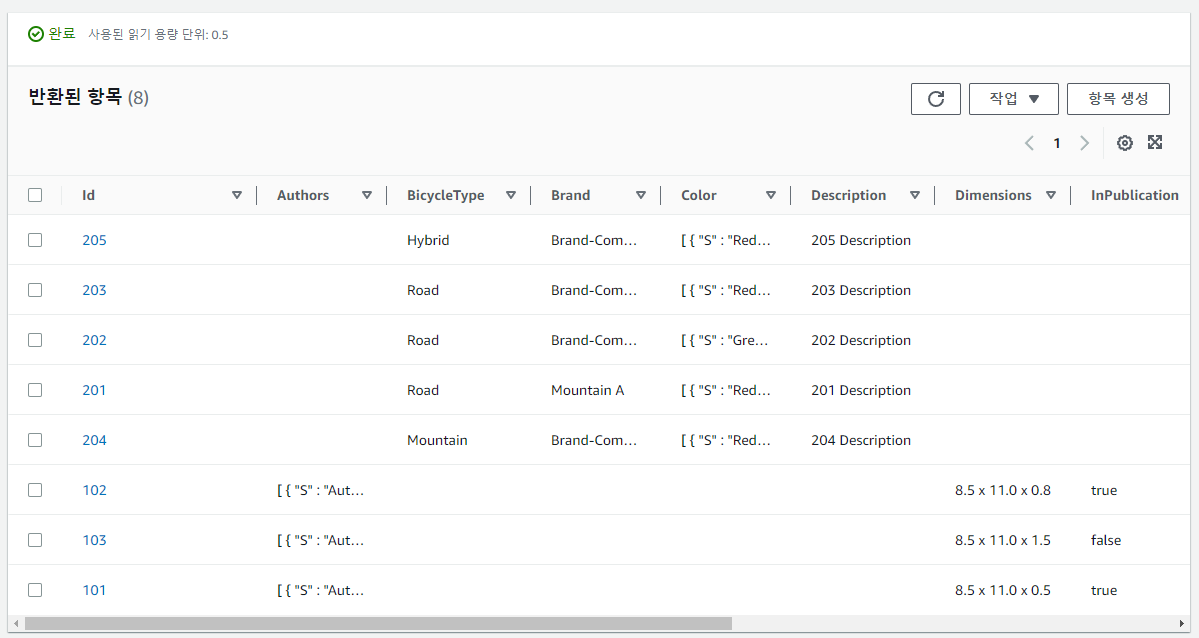
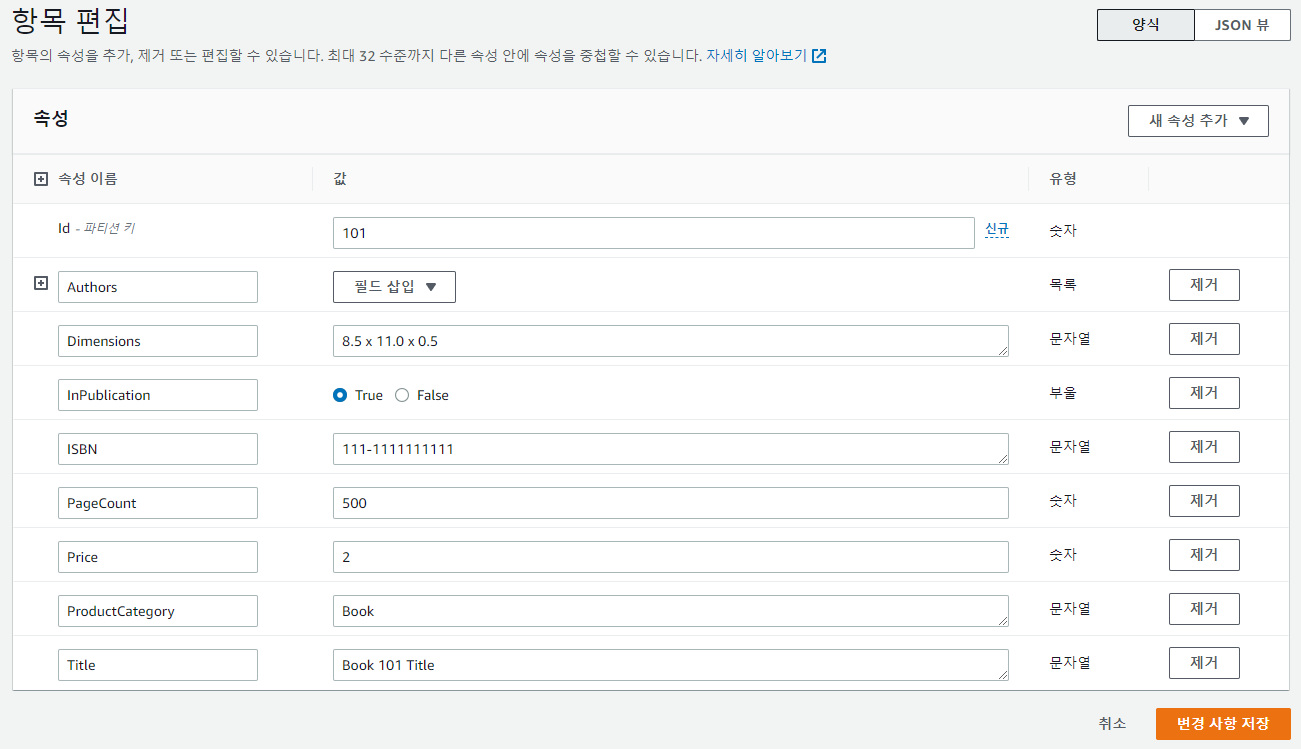
아이템들 중 101을 클릭해보면 편집기를 확인할 수 있고, 모든 속성을 보고 수정할 수 있다!
쿼리를 사용해 아이템 컬렉션을 읽어보자.
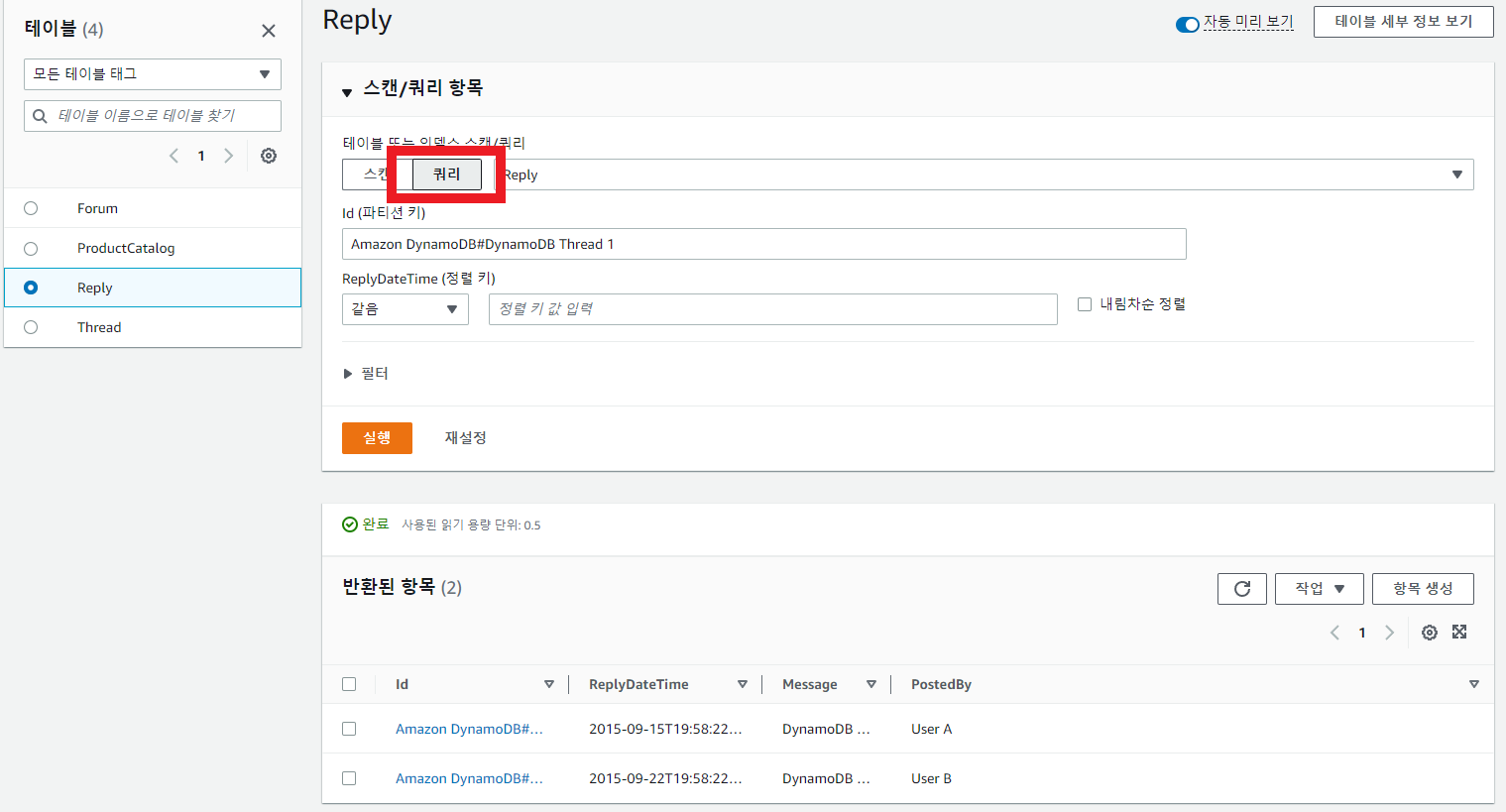
위와 같이 쿼리를 간단하게 사용 가능하다.
필터 또한 추가 가능하다!
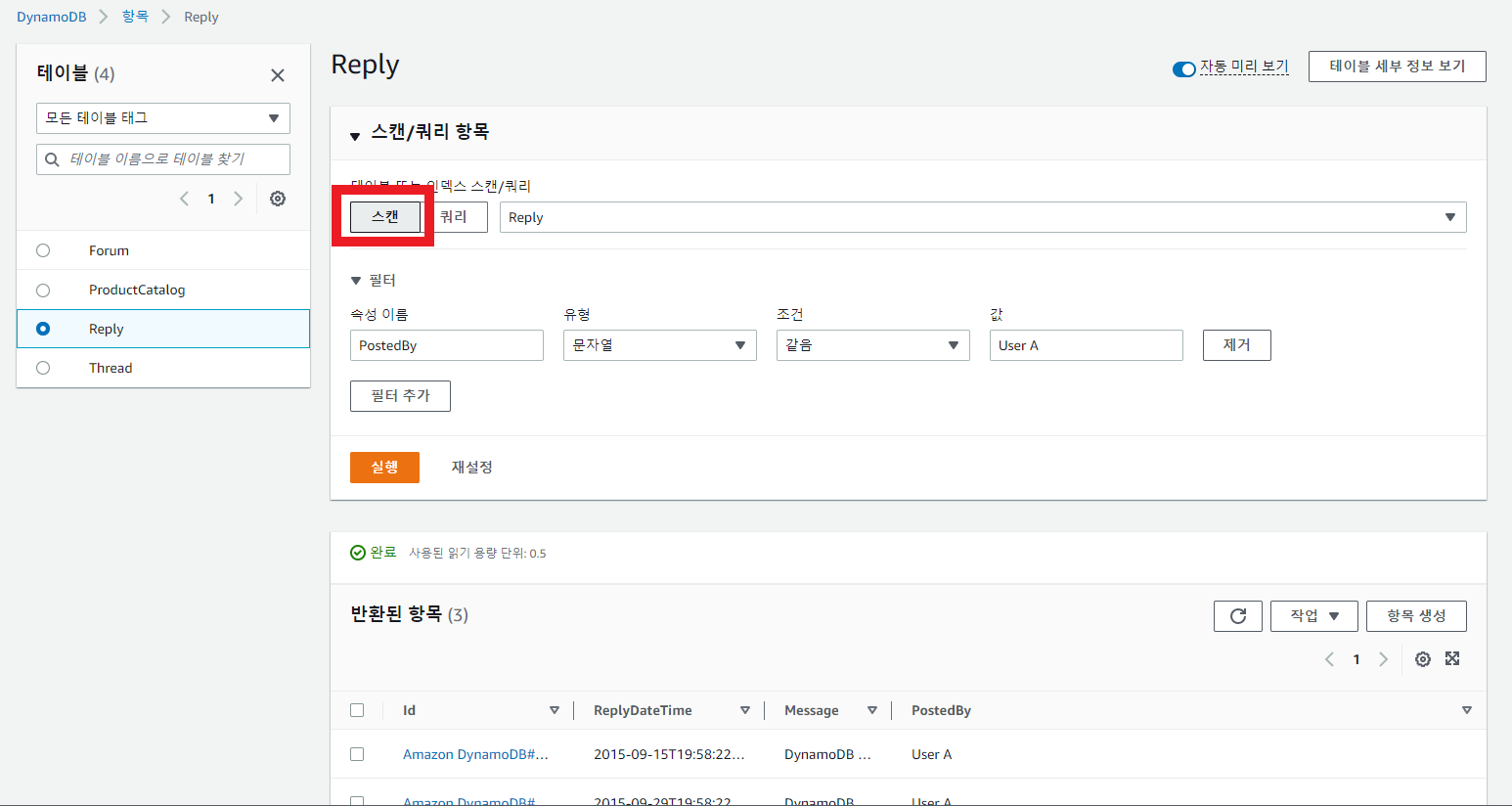
위와 같이 스캔도 가능!
이번엔 GSI 생성 해보자.
인덱스 생성을 클릭하면,
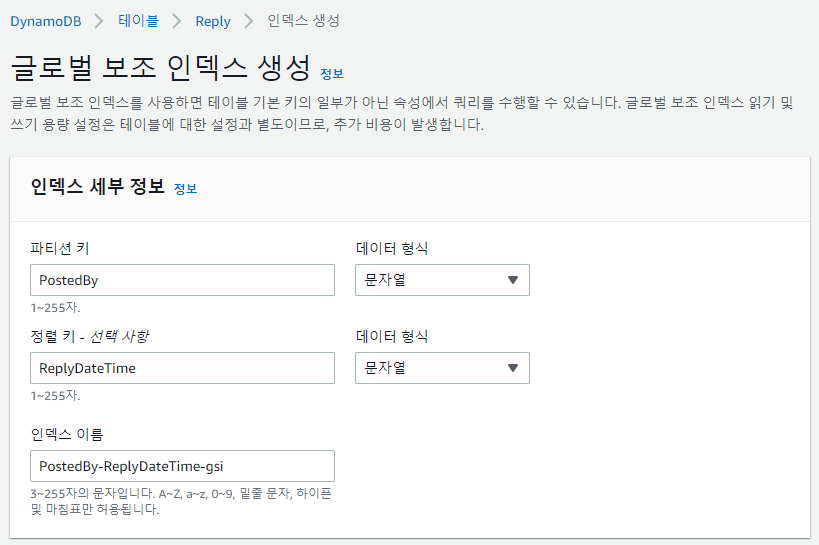
위와 같이 생성해주면 된다.
생성이 끝나고 다시 해당 테이블에 대해 쿼리를 해주려 들어가면..
Table / index 선택 항목이 생겨 있다!
❗ 여까지 간단하게 DynamoDB 다루는 방법에 대해 알아봤고..
다음엔 백업 + RDBMS에서 마이그레이션 해오는 방법을 알아보도록 하자!! ❗
'Cloud > AWS' 카테고리의 다른 글
| [AWS] Windows Server RDP 접속 (0) | 2022.12.09 |
|---|---|
| [AWS] Serverless Service - DynamoDB 편(4) (0) | 2022.12.08 |
| [AWS] Serverless Service - DynamoDB 편(2) (0) | 2022.12.05 |
| [AWS] Serverless Service - DynamoDB 편(1) (0) | 2022.12.02 |
| [AWS] AppStream 2.0 (0) | 2022.11.26 |