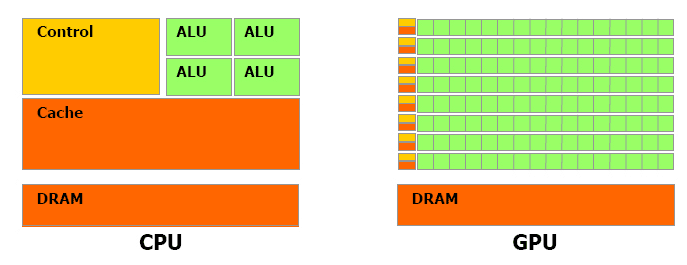
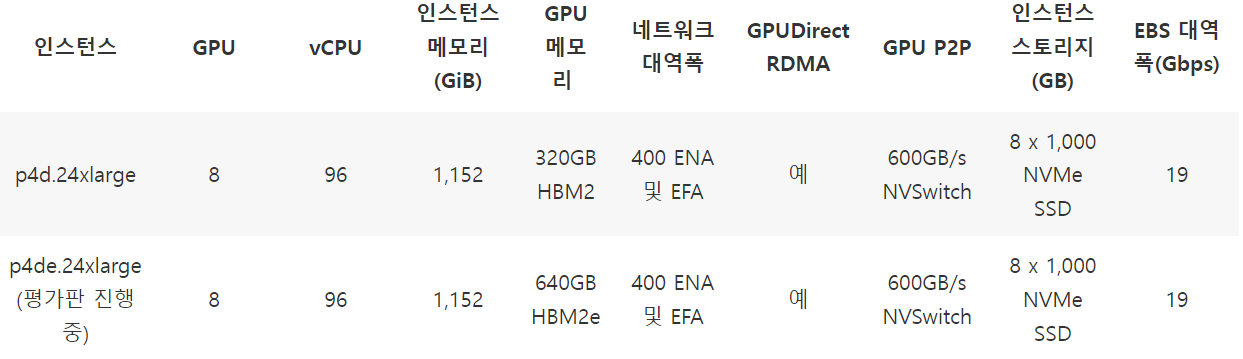
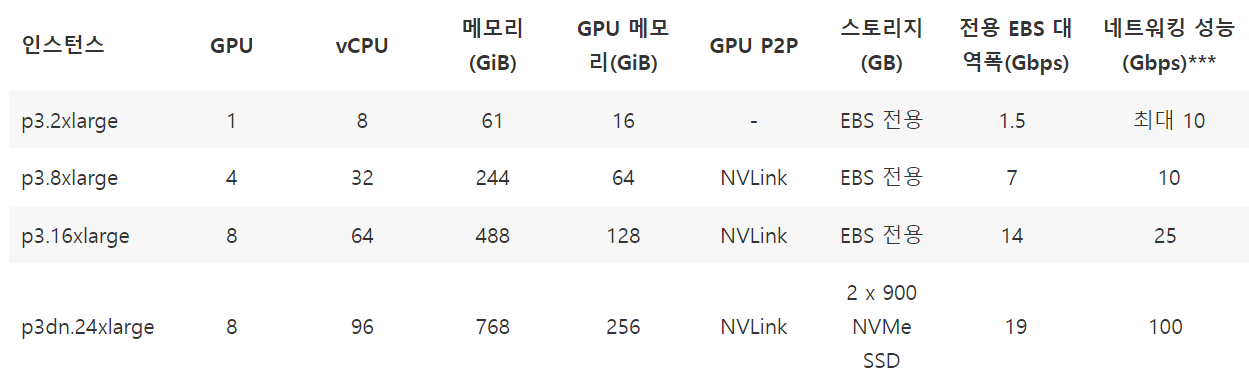
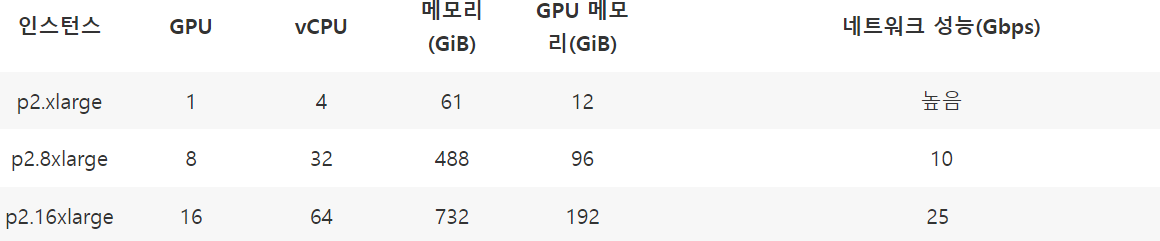
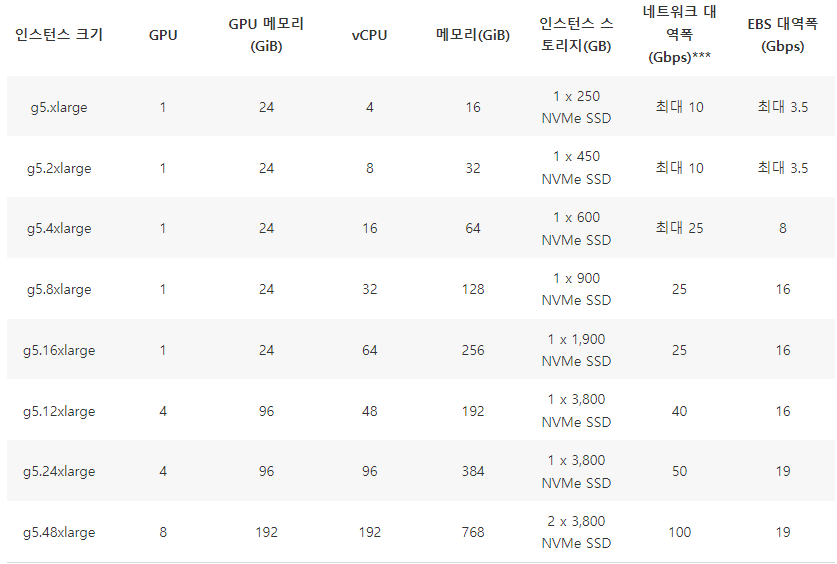
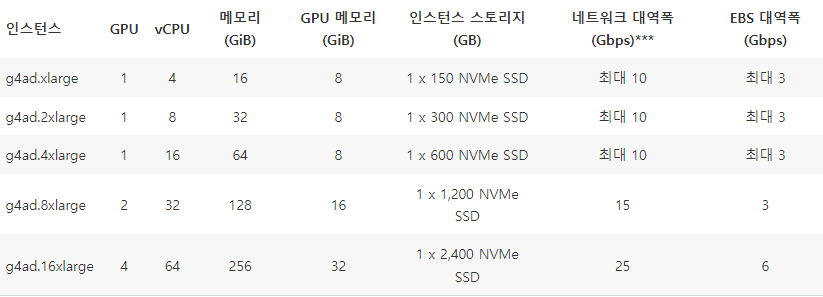
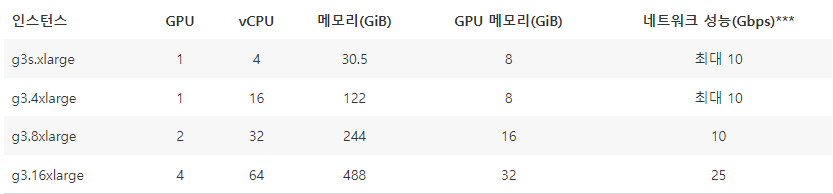
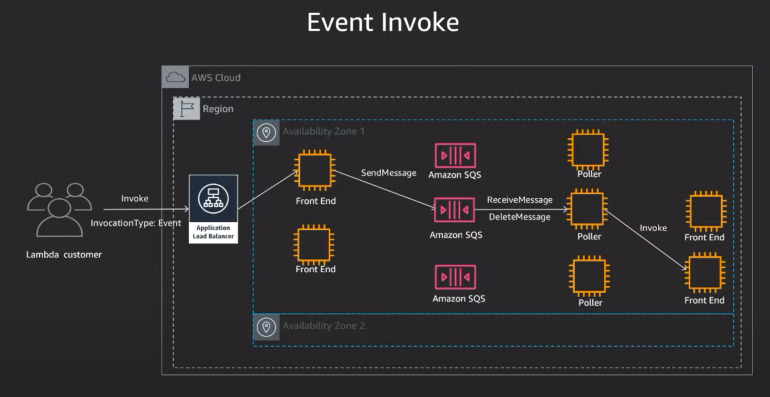
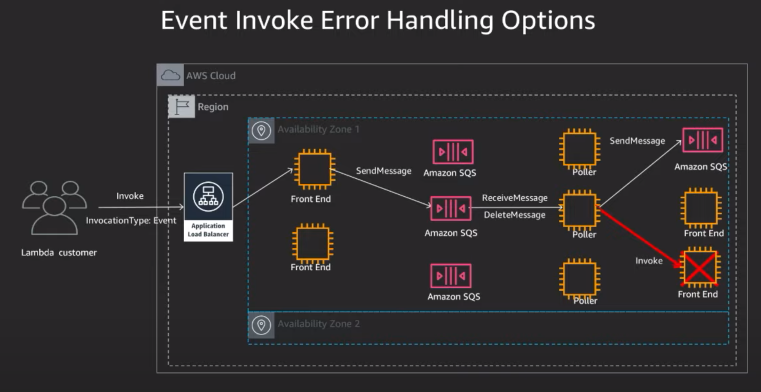
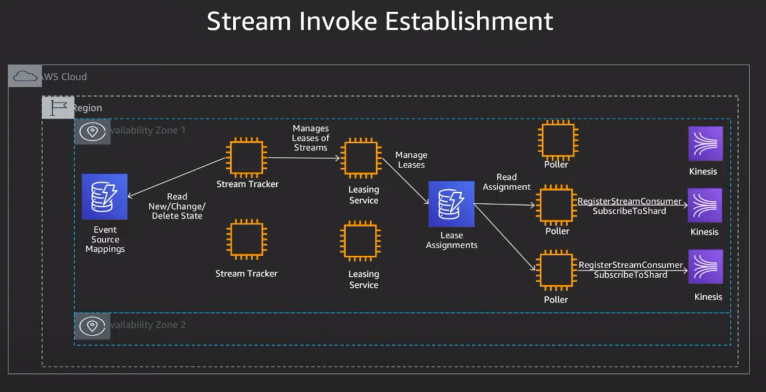
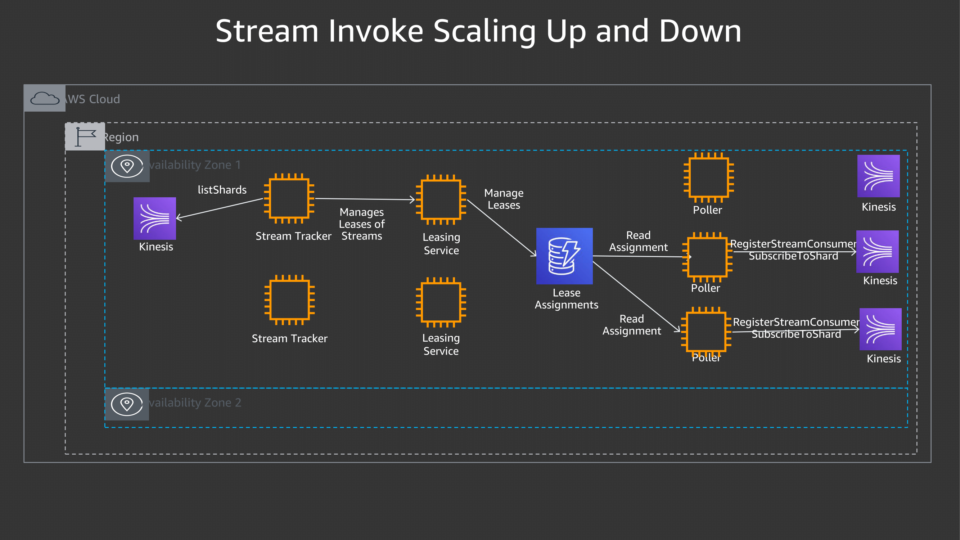
일단 방법에 뭐가 있는지 생각해보자.
그냥 단순하게 생각해봤을 떄, 제일 먼저 생각 나는 건 lambda이다.
해당 lambda가 인스턴스를 시작/중지 시킬 수 있을 것이다. 그럼 다음으로 생각해봐야 할 것은 lambda를 누가 호출 할 것이냐인데... 이 기준은 사용자가 정하면 된다. 보통 EventBridge로 스케줄링 한다.
정리해보면 EventBridge가 Lambda를 호출하고 해당 Lambda가 인스턴스를 중지/시작 시켜 줄 것이다.
이를 잘 활용해서 사용하면 원하는 시간대에 자동으로 시작/중지를 할 수 있을 것 같다!
인스턴스 생성

위와 같은 태그를 가진 인스턴스를 생성해준다.
- auto-schedule: True 인 태그를 가진 인스턴스만 스케줄링
Lambda 생성
1) IAM Role과 Policy 생성
Lambda에 EC2 인스턴스 시작 및 종료에 관한 권한이 필요하다.
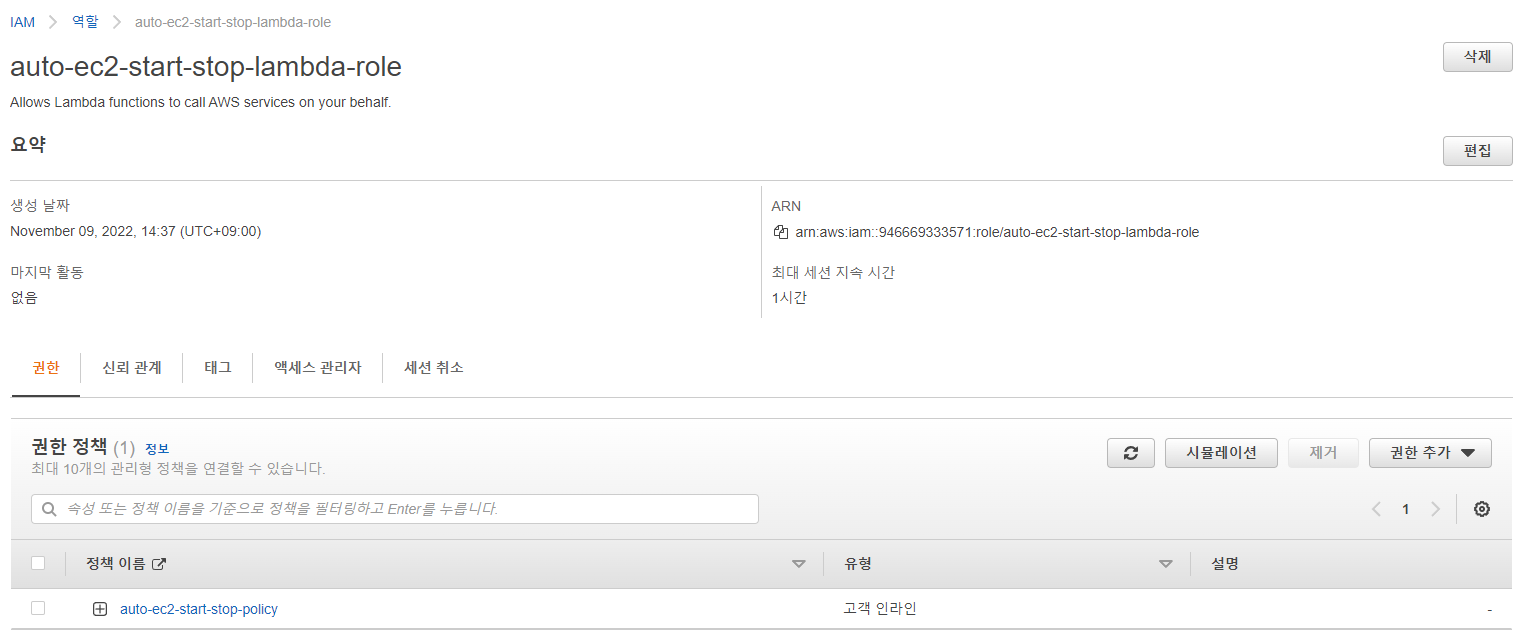
인라인 정책으로 넣어줬다
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"ec2:Describe*",
"ec2:Start*",
"ec2:Stop*"
],
"Resource": "*"
}
]
}2) EC2 start 함수 생성
위에서 만들었던 역할로 연결해줘야한다.
import boto3
region = 'ap-northeast-2'
instances = []
ec2_r = boto3.resource('ec2')
ec2 = boto3.client('ec2', region_name=region)
for instance in ec2_r.instances.all():
for tag in instance.tags:
if tag['Key'] == 'auto-schedule':
if tag['Value'] == 'True':
instances.append(instance.id)
def lambda_handler(event, context):
ec2.start_instances(InstanceIds=instances)
print('started your instances: ' + str(instances))
제한 시간을 30초로 변경해준다.
그리고 그냥 아무 테스트 만들어서 돌려준다. 성공 로그 뜨면 완료.
3) EC2 stop 함수 생성
코드만 바뀌고 다른 과정은 위의 EC2 start 함수와 같다.
import boto3
region = 'ap-northeast-2'
instances = []
ec2_r = boto3.resource('ec2')
ec2 = boto3.client('ec2', region_name=region)
for instance in ec2_r.instances.all():
for tag in instance.tags:
if tag['Key'] == 'auto-schedule':
if tag['Value'] == 'True':
instances.append(instance.id)
def lambda_handler(event, context):
ec2.stop_instances(InstanceIds=instances)
print('stopped your instances: ' + str(instances))
해당 ec2가 중지 중인걸 볼 수 있음!

EventBridge 설정
규칙을 원하는대로 설정해서 생성하면 된다.(월-금 오전 9시 - 오후 6시까지 start, 나머지 stop)
- 이름: auto-ec2-start-rule / auto-ec2-stop-rule
- 이벤트 버스: 일단은 default로 진행
- 규칙 유형: 일정 선택
- 일정 패턴: cron " 0 0 ? * MON-FRI * " / " 0 9 ? * MON-FRI * "

- 대상: AWS 서비스 - lambda 위에서 생성한 함수 지정

시간은 UTC 기준이니 참고!!(00:00 UTC는 한국 시간으로 오전 9시)
'Cloud > AWS' 카테고리의 다른 글
| [AWS] Spot Fleet (0) | 2022.11.16 |
|---|---|
| [AWS] Lambda와 RDS Proxy (0) | 2022.11.14 |
| [AWS] GPU 인스턴스 Spot Fleet (0) | 2022.11.12 |
| [AWS] GPU 인스턴스 유형(EC2) (0) | 2022.11.12 |
| [AWS] Lambda에 X-Ray 적용하기 (0) | 2022.11.06 |