Athena 사용법: https://realyun99.tistory.com/147
[AWS] Amazon Athena 사용법
먼저 Athena가 뭐하는 친군지 살펴보자. Amazon Athena 표준 SQL을 사용해 S3에 저장된 데이터를 간편하게 분석할 수 있는 대화식 쿼리 서버리스 서비스 그냥 단순히 S3에 저장된 데이터를 가리키고 스
realyun99.tistory.com
저번 포스팅에 이어서 Glue까지 사용을 해보자. 사용 전에 Glue가 뭔지 부터 확인하자.
AWS Glue
- 분석, 기계 학습 및 애플리케이션 개발을 위해 데이터를 쉽게 탐색, 준비, 조합할 수 있도록 지원하는 서버리스 데이터 통합 서비스
- 데이터 통합: 해당 개발을 위해 데이터를 준비하고 결합하는 프로세스
- 데이터 검색 및 추출
- 데이터 강화, 정리, 정규화 및 결합
- 데이터베이스, 데이터 웨어하우스 및 데이터 레이크에 데이터 로드 및 구성 등
- 기능
- Data Catalog: 모든 데이터 자산을 위한 영구 메타데이터 스토어
- 모든 AWS 데이터 세트에서 검색: 자동으로 통계를 계산하고 파티션을 등록, 데이터 변경 사항 파악
- Crawlers: 소스/대상 스토어에 연결해 우선순위가 지정된 Classifiers을 거치면서 데이터의 스키마 결정, 메타 데이터 생성
- Stream schema registries: Apache Avro 스키마를 사용해 스트리밍 데이터의 변화를 검증하고 제어
- Data Integration and ETL(Extract / Transform / Load)
- Studio Job Notebooks: Studio에서 최소한으로 설정할 수 있는 서버리스 노트북
- Interactive Sessions: 데이터 통합 작업 개발을 간소화, 엔지니어와 대화식으로 데이터 탐색, 준비
- ETL 파이프라인 구축: 여러 개의 작업을 병렬로 시작하거나 작업 간에 종속성을 지정
- Studio: 분산 처리를 위한 확정성이 뛰어난 ETL 작업 가능, 에디터에서 ETL 프로세스를 정의하면 Glue가 자동으로 코드 생성
- 등등...
- Glue DataBrew: 시각적 데이터 준비 도구(사전 빌드된 250개 이상의 변환 구성 중 선택해서 코드 없이 가능)
- Data Catalog: 모든 데이터 자산을 위한 영구 메타데이터 스토어
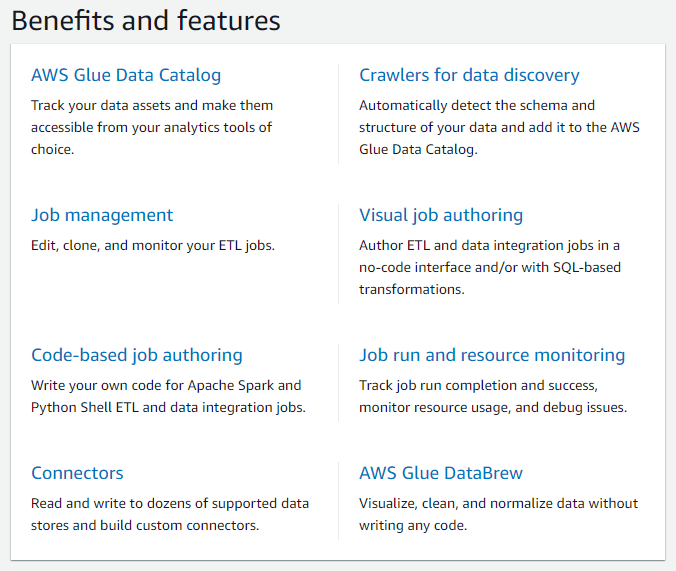
솔직히 뭐라고 하는지 모르겠다.. 직접 써보는게 답!
Crawler로 실습을 진행해보자.
- Glue로 테이블 만들기
크롤러를 생성해주자.
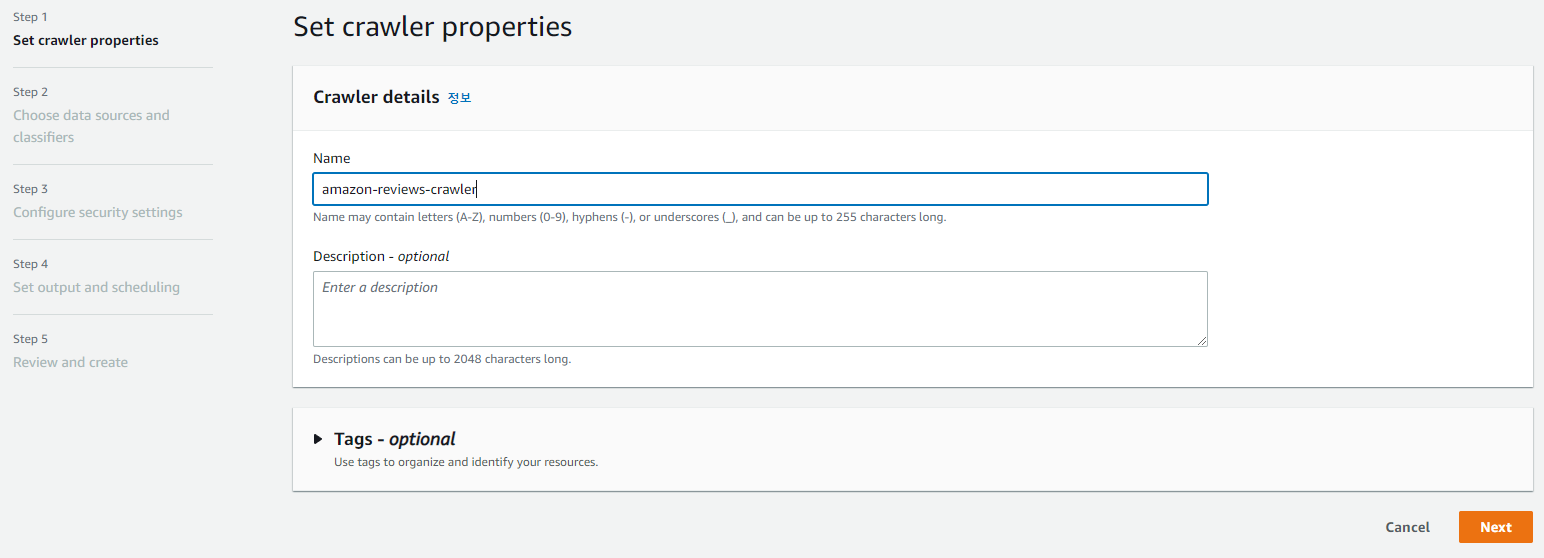
데이터 스토어는 저번 포스팅 때 가져왔었던 데이터셋이 위치한 버킷으로 지정할 것!


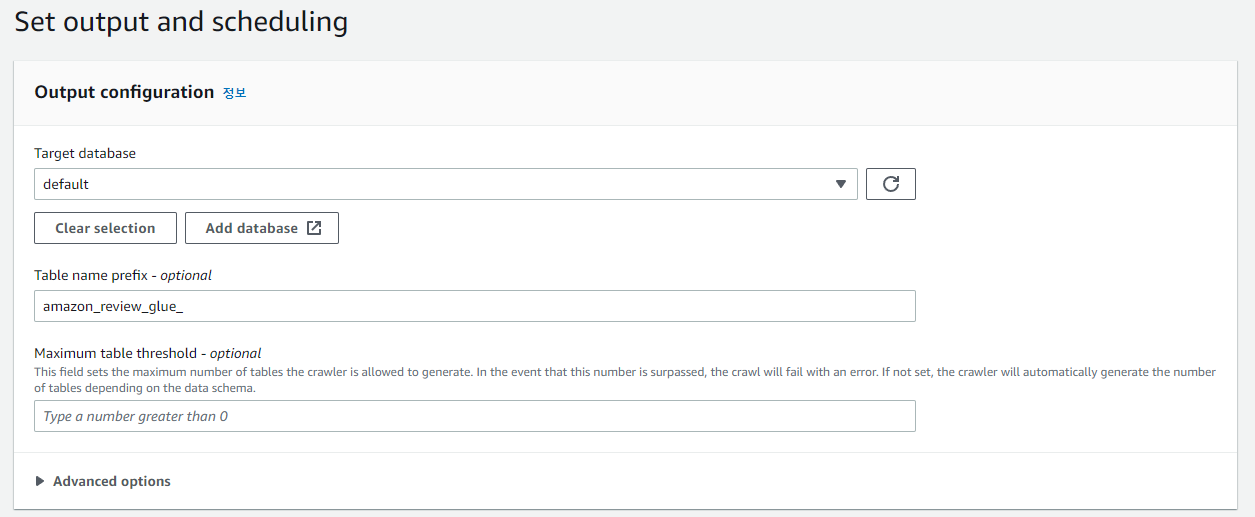
Create new IAM role을 통해 새로 생성하고 지정해준다. 타겟 DB까지 정해주면 끝!
크롤러를 돌려주자(생성된 크롤러 선택 후 Run 버튼 클릭)

Glue → Tables에 들어가면 테이블이 하나 더 추가된 것을 볼 수 있다.

Athena로 돌아가 다음 쿼리를 실행해 데이터를 확인해보자.
select * from amazon_review_glue_parquet limit 10;
- Views 만들기
다시 Athena로 돌아왔다.(Athena의 view는 물리적 테이블이 아닌 논리적 테이블!)
저장된 쿼리에서 Athena_create_view_top_rated를 클릭한다.
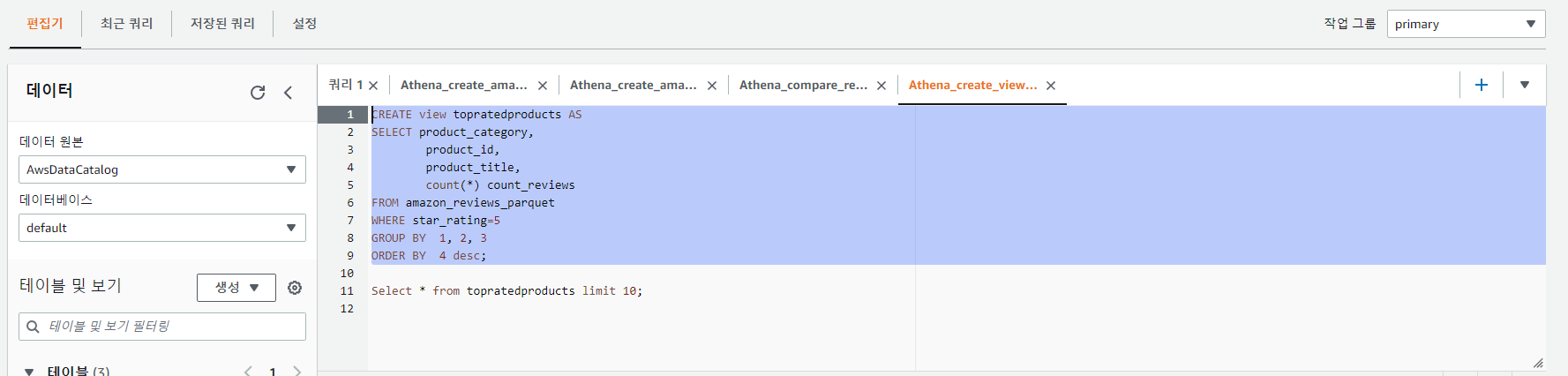
위 이미지 처럼 선택 후 실행한다. 아래와 같이 보기에 추가된 것을 확인할 수 있다.
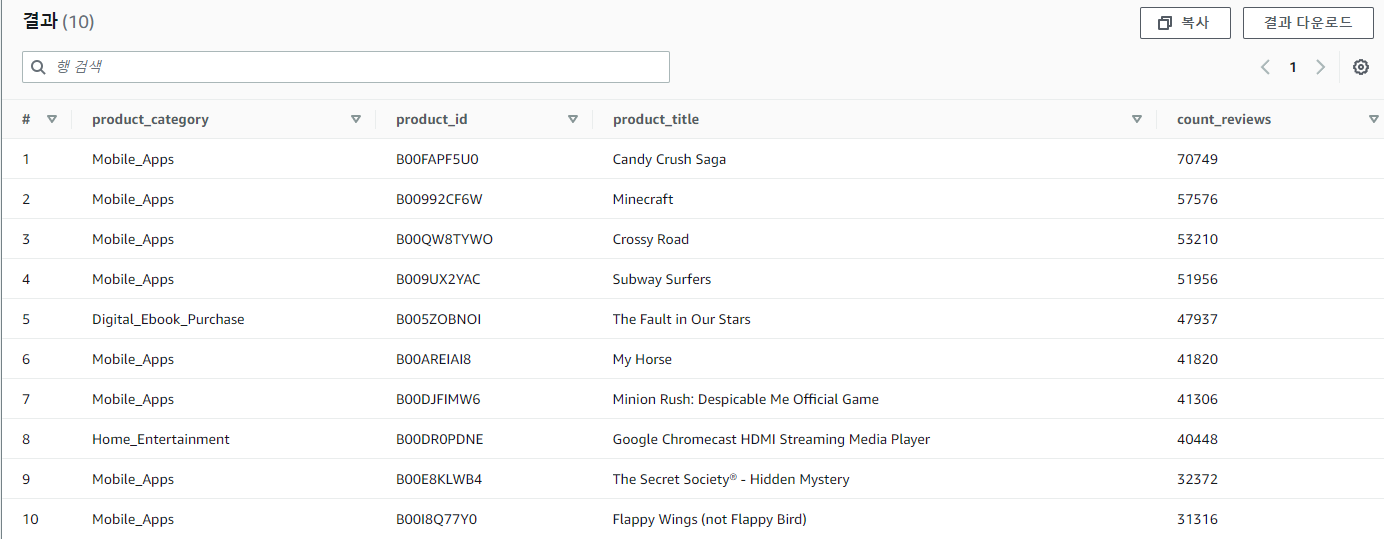
두번째 쿼리를 선택한 뒤 실행해 등급별로 상위 10개 제품을 확인해보자.
- 결과 확인(S3 버킷)
S3에서 athena-workshop-<account-id> 로 시작하는 버킷을 찾아 들어가면 처음엔 비어있던 버킷이 Athena에서 돌렸던 쿼리문을 기준으로 폴더들이 생성되어 있는 것을 볼 수 있고, Athena_compare_reviews 접두사 중 하나를 찾아보면 쿼리 ID와 함께 저장된 결과를 볼 수 있음.

❗ 그래서 결과적으로 Glue Crawler가 무슨 역할을 했냐...? ❗
크롤러 작동 방식:
데이터를 분류하여 raw data의 포맷, 스키마 및 관련 속성 결정 / 데이터를 테이블 혹은 파티션으로 분류 / 메타데이터를 Data Catalog에 작성
위와 같은 것들을 crawler를 생성하고 실행하면 알아서 해주는 느낌인듯?
데이터 스토어를 지금은 하나를 지정했지만, 여러 개 병렬로도 가능하고...
지금 했던 실습 같은 경우는 아주 단순한 경우인 거고, 여러 방식으로 활용이 가능하다!
(그리고 Athena는 쿼리를 돌려서 테이블을 만들었지만, 크롤러는 그런게 없이 알아서 돌려주네?!)
'Cloud > AWS' 카테고리의 다른 글
| [AWS] Amazon QuickSight 개념 및 실습 (0) | 2022.11.20 |
|---|---|
| [AWS] Amazon Athena 사용법 -3 (0) | 2022.11.20 |
| [AWS] Amazon Athena 사용법 -1 (1) | 2022.11.19 |
| [AWS] Step Functions (0) | 2022.11.18 |
| [AWS] Spot Fleet (0) | 2022.11.16 |