요즘 GPU 인스턴스에 사람들의 관심이 높아져 가고 있다.
그래서 해당 유형들이 뭘 나타내고 어느정도의 사양인지 간단히 정리해보려 한다..
근데 사실 GPU가 뭔지도 제대로 모르고 있다...
GPU가 뭔지 간단하게 알아보면,
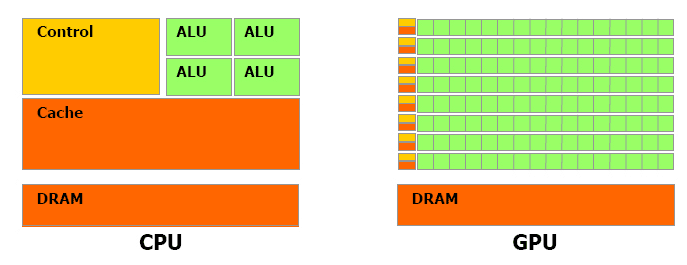
- ALU: 산출 연산 처리 장치(연산 담당)
- CU: 컨트롤 유닛(명령어 해석 및 실행)
GPU의 경우 CPU에 비해 월등하게 ALU 개수가 많다. 병렬 처리 방식을 위해 그런 것!
그래서 AI에 많이 사용된다. "AI는 단순 반복 연산을 처리하여 학습하는 특성"을 가지고 있어 병렬 구조로 연산하는 GPU 칩셋이 중요해진다!
그리고 GPU와 다른 리소스 들 사이의 병목 현상을 해결하는게 주요 문제이다.. 아래는 이를 해결할 수 있는 기술들!
(참고: https://www.youtube.com/watch?v=w_CkMjH8tm4 )
- GPU Direct RDMA: NIC에 있는 버퍼를 GPU가 바로 읽을 수 있게 해주는 기술
- RDMA(Remote Direct Memory Access): 컴퓨터 간 CPU를 거치지 않고 메모리 끼지 직접 데이터를 주고 받게 하는 기술
- GPU P2P: GPU Direct P2P, Memory 까지 다녀오는게 아닌 GPU 메모리 끼리 참조할 수 있도록
- P2P(Peer to Peer): GPU - GPU 간의 사이 연결
- GPU Direct Storage 까지..
(참고로 GPU는 CPU와 비슷하지만, 용도가 다를 뿐.. CPU에 비해 더 작고 전문화된 코어로 구성된 프로세서)
(vCPU: 나누기 2를 해야 실제 물리 코어, 스레드라 생각하면 될듯)
일단 AWS는 GPU 인스턴스를 사용하는 유형들을 가속화된 컴퓨팅(Accelerated Computing) 쪽으로 분류한다.
 가속화된 컴퓨팅 유형
가속화된 컴퓨팅 유형
P 유형
- P4
- 최신 세대의 GPU 기반 인스턴스, 기계 학습 / 고성능 컴퓨팅 + 최고의 성능
- ENA / EFA:
- ENA(Elastic Network Adapter): 향상된 네트워킹 제공, 높은 처리량과 PPS(초당 패킷) 성능 높게..
- EFA(Elastic Fabric Adapter): 추가 OS 우회 기능이 있는 ENA, 대규모 HPC 앱과 같은 높은 수준의 인스턴스 간 통신을 실행할 수 있도록
- NVSwitch: NVLink의 고급 통신 기능을 구축해 더 높은 대역폭과 지연 시간 절감(여러 NVLink 연결)
- NVMe SSD: Non-Volatile Memory, 비휘발성 메모리(RAM과 비슷하지만 다른 점)
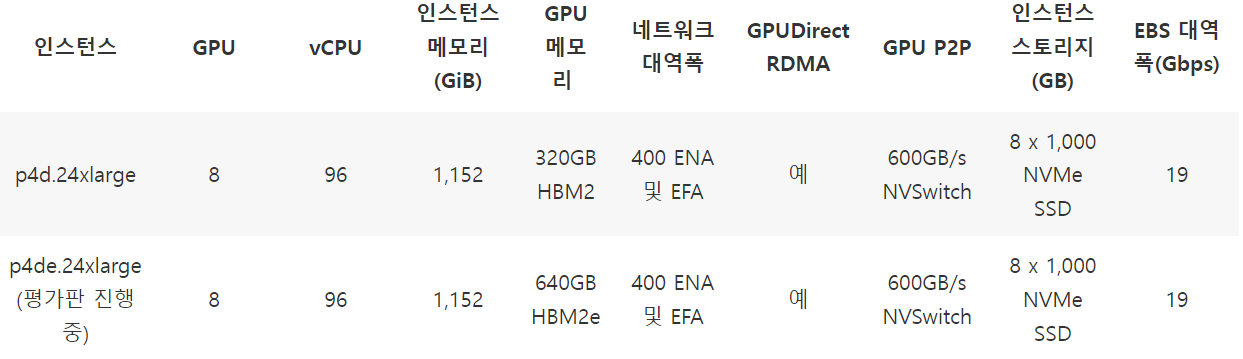 P4 - NVIDIA A100 Tensor Core GPU
P4 - NVIDIA A100 Tensor Core GPU
- P3
- 머신 러닝/딥 러닝, 고성능 컴퓨팅
- NVLink: 높은 대역폭과 향상된 확장성
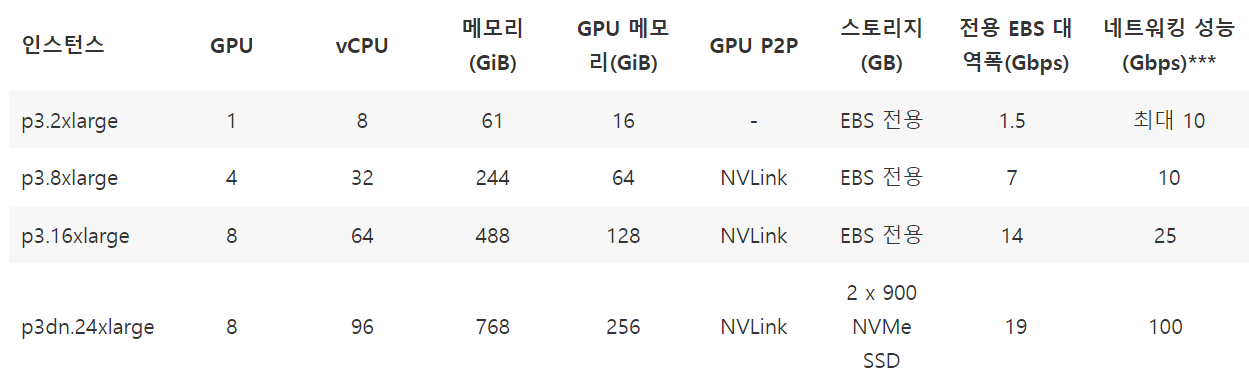 P3 - NVIDIA Tesla V100 GPU
P3 - NVIDIA Tesla V100 GPU
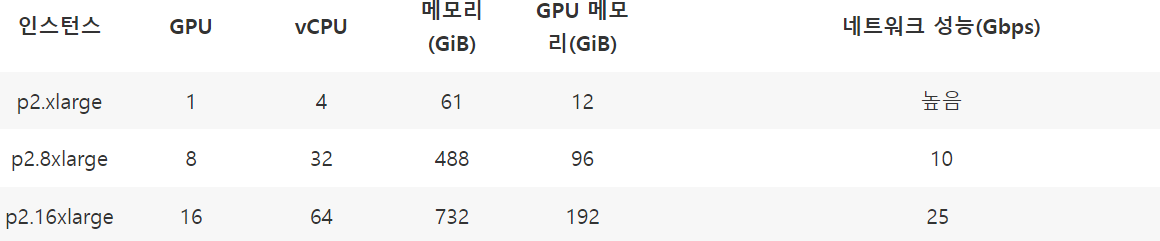 P2 - NVIDIA K80 GPU
P2 - NVIDIA K80 GPU
G 유형
- G5
- 그래픽 집약적인 애플리케이션, 기계 학습 추론 가속화
- 간단한 기계 학습 모델에서 중간 정도의 복잡한 기계 학습 모델까지 훈련하는데 사용 가능
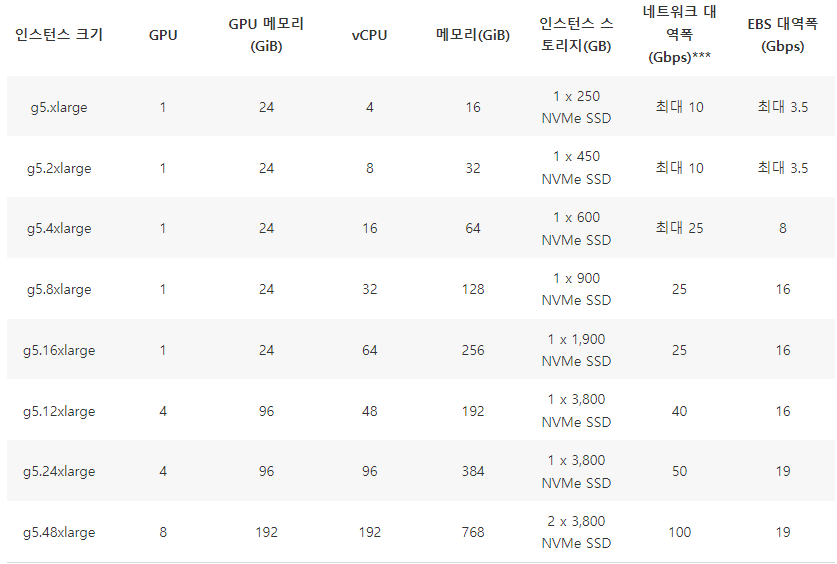 G5 -NVIDIA A10G Tensor Core GPU
G5 -NVIDIA A10G Tensor Core GPU
- G5g
- AWS Graviton2 프로세서, 그래픽 워크로드에 대해 EC2에서 최고의 가격 대비 성능 제공
 G5g - NVIDIA T4G Tensor Core GPU
G5g - NVIDIA T4G Tensor Core GPU
 G4dn - NVIDIA T4 Tensor Core GPU
G4dn - NVIDIA T4 Tensor Core GPU
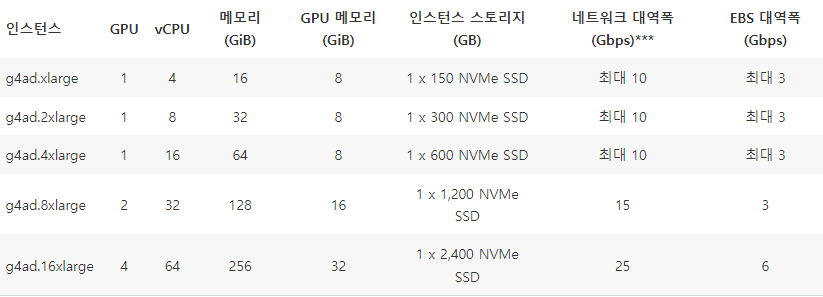 G4ad - AMD Radeon Pro V520 GPU
G4ad - AMD Radeon Pro V520 GPU
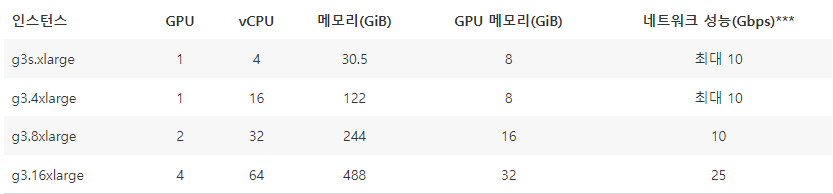 G3 - NVIDIA Tesla M60 GPU
G3 - NVIDIA Tesla M60 GPU
F 유형
 F1 - FPGA
F1 - FPGA
- FPGA: field programmable gate array, 프로그래머블 반도체 - 용도에 따라 내부 회로를 바꿀 수 있음(GPU와 다름)
- CPU, GPU는 용도가 정해진 주문형 반도체와 다르게 칩 내부를 용도에 따라 바꿀 수 있음
- AI 연산을 하는 GPU의 경우 원래의 용도에서 벗어난다. 이를 보완 가능!(딥러닝 학습, 추론 가능)
❗ 여기에 추가적으로 Trn1 유형 정도 괜찮을 듯 싶다. ❗
(Trn1: AWS Trainium 칩으로 구동, GPU 기반 인스턴스 대비 최대 50% 저렴한 훈련 비용)