Athena 사용법: https://realyun99.tistory.com/147
[AWS] Amazon Athena 사용법
먼저 Athena가 뭐하는 친군지 살펴보자. Amazon Athena 표준 SQL을 사용해 S3에 저장된 데이터를 간편하게 분석할 수 있는 대화식 쿼리 서버리스 서비스 그냥 단순히 S3에 저장된 데이터를 가리키고 스
realyun99.tistory.com
Athena+Glue(Crawler) 활용: https://realyun99.tistory.com/148
[AWS] Amazon Athena + Glue(Crawler) 활용
Athena 사용법: https://realyun99.tistory.com/147 [AWS] Amazon Athena 사용법 먼저 Athena가 뭐하는 친군지 살펴보자. Amazon Athena 표준 SQL을 사용해 S3에 저장된 데이터를 간편하게 분석할 수 있는 대화식..
realyun99.tistory.com
저번 포스팅들에 이어서 계속 진행해볼 것...
- Athena CTAS를 사용한 ETL
대부분의 경우 데이터 레이크 또는 테이블로 들어오는 raw data는 csv 또는 텍스트 형식이다.
이런 형식은 Athena, 기타 엔진으로 쿼리하는 데 최적이 아니다. 데이터를 parquet과 같은 포맷으로 변환하는 것이 좋다.
CTAS(Create Table As Select) 쿼리를 사용해 테이블을 tsv 형식에서 parquet 포맷으로 변환하고 압축 및 분할을 통해 저장할 것..
저장된 쿼리에서 Athena_ctas_reviews를 실행해보자

(s3 버킷 이름을 잘 설정 해주자!)
다음 쿼리를 실행하면 다음과 같이 결과를 볼 수 있다.
명령들을 좀 살펴보자!
CREATE TABLE amazon_reviews_by_marketplace
WITH ( format='PARQUET', parquet_compression = 'SNAPPY', partitioned_by = ARRAY['marketplace', 'year'],
external_location = 's3://<<Bucket-name>>/athena-ctas-insert-into/') AS
SELECT customer_id,
review_id,
product_id,
product_parent,
product_title,
product_category,
star_rating,
helpful_votes,
total_votes,
verified_purchase,
review_headline,
review_body,
review_date,
marketplace,
year(review_date) AS year
FROM amazon_reviews_tsv
WHERE "$path" LIKE '%tsv.gz';
/* Let's try to find the products and their corresponding category by number of reviews and avg star rating for US marketplace in year 2015 */
SELECT product_id,
product_category,
product_title,
count(*) AS num_reviews,
avg(star_rating) AS avg_stars
FROM amazon_reviews_by_marketplace
WHERE marketplace='US'
AND year=2015
GROUP BY 1, 2, 3
ORDER BY 4 DESC limit 10;parquet_compression = 'SNAPPY' 같은 경우는 압축 방식을 정하는 것..
https://docs.aws.amazon.com/ko_kr/athena/latest/ug/compression-formats.html
Like 구문: SELECT * FROM [table name] WHERE [column] LIKE [condition];
부분적으로 일치하는 컬럼을 찾을 때 사용
- Athena Workgroups
Workgroup: 사용자, 팀, 애플리케이션 또는 워크로드를 분리하고 각 쿼리 또는 전체 workgroup이 처리할 수 있는 데이터 양에 대한 제한을 설정하고 비용을 추적한다.
"Workgroup이 리소스 역할을 하기 때문에 리소스 수준 ID 기반 정책을 사용해 특정 workgroup에 대한 액세스 제어 가능!"
저번 포스팅의 테이블 생성 실습에서 primary 작업 그룹에 대한 CloudWatch 메트릭을 활성화했다.
CloudWatch 지표를 확인해보자(작업 그룹 → primary → 지표)

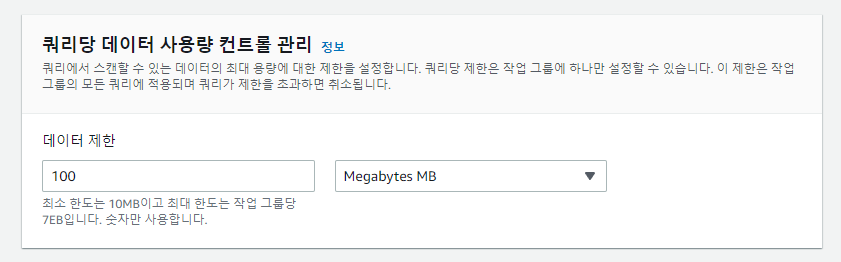
데이터 사용 제한을 설정해보자.
workgroupA를 클릭한 뒤 편집에 들어가 해당 데이터를 제한하자.
CloudFormation을 열고 스택 출력에 들어가 ConsolePassword 링크 클릭(AWS Secrets Manager로 이동)


해당 암호 값 검색을 통해 비밀번호를 확인하자.
시크릿 탭을 열어
IAM user name: userA
Password: 복사한 비밀번호 로 로그인하자.
Athena 콘솔을 열고 쿼리 결과 위치에 primary 위치를 입력한 다음 wrokgroupA를 선택하자.
(참고로 현재 실습은 버지니아 북부에서 진행 중이다!)

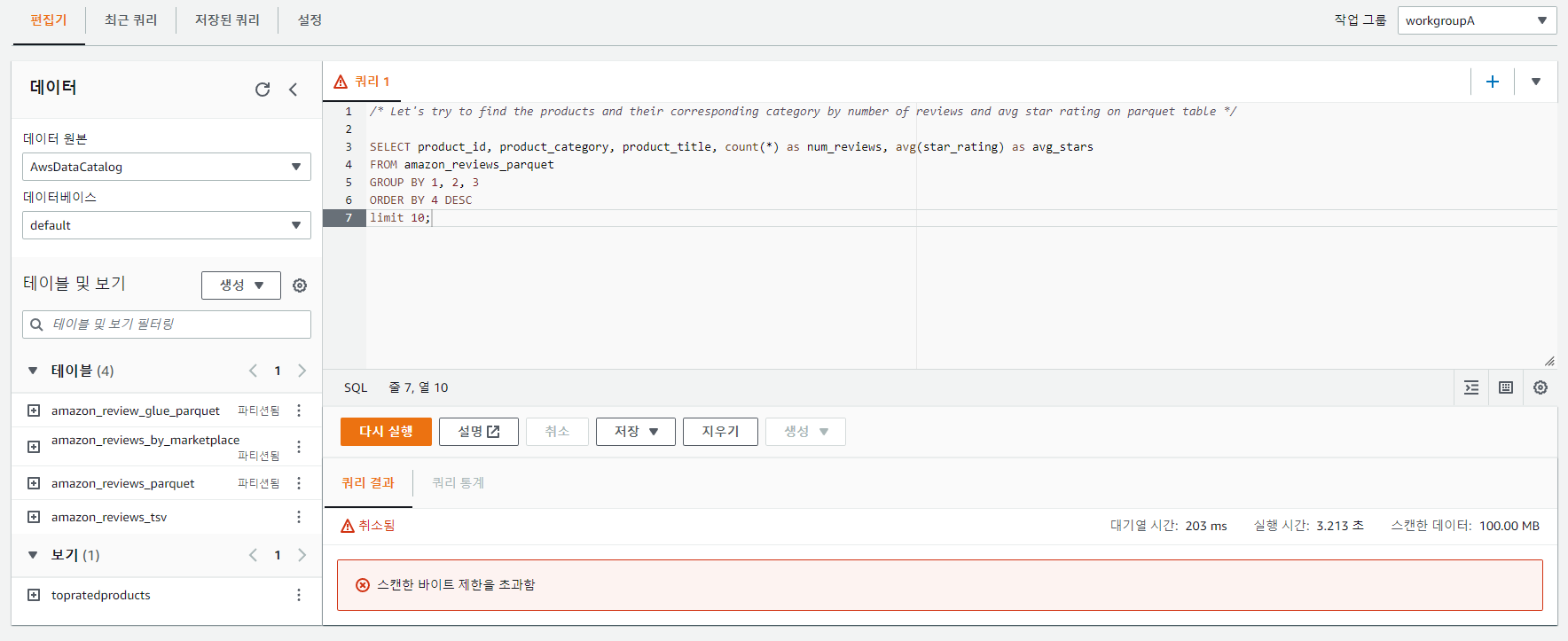
쿼리를 실행해보면 실행 불가!
실행했던 쿼리문이다..
/* Let's try to find the products and their corresponding category by number of reviews and avg star rating on parquet table */
SELECT product_id, product_category, product_title, count(*) as num_reviews, avg(star_rating) as avg_stars
FROM amazon_reviews_parquet
GROUP BY 1, 2, 3
ORDER BY 4 DESC
limit 10;
다음으로 workgroupB로 전환하고 userA가 workgroupB에서 동일한 쿼리를 실행할 수 있는지 확인해보자.
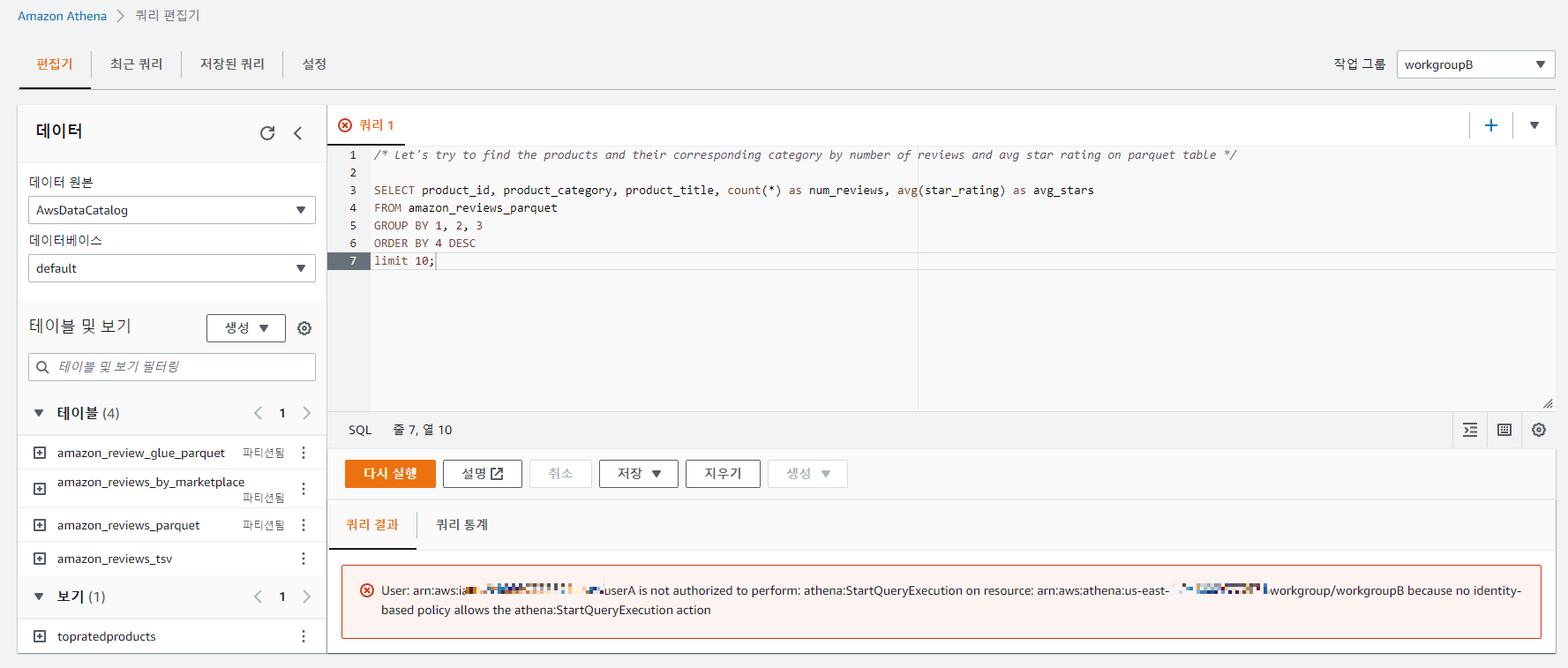
권한이 없어 할 수 없다는 오류가 발생한다.
'Cloud > AWS' 카테고리의 다른 글
| [AWS] AppStream 2.0 (0) | 2022.11.26 |
|---|---|
| [AWS] Amazon QuickSight 개념 및 실습 (0) | 2022.11.20 |
| [AWS] Amazon Athena 사용법 -2 + Glue(Crawler) 활용 (1) | 2022.11.19 |
| [AWS] Amazon Athena 사용법 -1 (1) | 2022.11.19 |
| [AWS] Step Functions (0) | 2022.11.18 |